1 AIS-based emissions model
1.1 Methods
1.1.1 Model Overview
We estimate emissions using an engineering bottom-up approach based on AIS data, vessel characteristics, and emissions conversion factors from the literature. The model follows the methodology of the 2020 IMO “Fourth Greenhouse Gas Study” (Faber and Xing (2020)) and the 2017 ICCT “Greenhouse Gas Emissions From Global Shipping” study (Olmer et al. (2017)), applied to the GFW data.
From a high level, we calculate emissions as follows:
For each individual AIS message (ping), we calculate the main engine use, auxiliary engine use, and boiler use, each of which is a function of vessel characteristics, speed, and the time since the previous ping.
Using emissions factors (EFs) for the main, auxiliary, and boiler engines, we calculate emissions of six pollutants (CO2, CH4, NOX, SOX, CO, and N2O) for each ping and each engine.
For each pollutant and ping, we sum the emissions across the main, auxiliary, and boiler engines to get ping-level emissions.
We derive three additional pollutants (PM2.5, PM10, and VOCs) by scaling each engine’s CO2 emissions factor by a fixed ratio. This gives us a total of nine reported pollutants: CO2, CH4, NOX, SOX, CO, N2O, PM2.5, PM10, and VOCs.
With ping-level emissions, we aggregate emissions by vessel, by voyage, by port stay, by time, by space, etc.
1.1.2 Main engine
1.1.2.1 Main engine energy use
Based on Faber and Xing (2020) (page 64), main engine energy use (in killowatt-hours) is calculated as follows:
\[\text{Main Engine Energy Use}_{kWh} = \text{Hours} \times \text{Load Factor} \times \text{Main Engine Power}_{kW} \] Where hours comes from each individual AIS message, main engine power (kW) comes from the vessel characteristics dataset, and the load factor comes from the product of several correction factors (CFs):
\[\text{Load Factor} = \text{Speed-power CF} \times \text{Hull Fouling CF} \times \text{Weather CF} \times \text{Draft CF}\] Where: - hull fouling CF is 1.07, reflecting a 7% increase in resistance as described in Olmer et al. (2017) and Faber and Xing (2020) (see page 17 and Annexes page 270, respectively) - weather CF is a correction factor based on weather conditions, varying with the distance to shore. This factor is set at 1.1 for nearshore activity (≤5 nm from shore) to account for a 10% increase in resistance, and 1.15 for offshore activity (>5 nm), reflecting a 15% increase in resistance, as described in the Olmer et al. (2017) and Faber and Xing (2020) (see pages 18 and 270, respectively). - draft CF is extracted from the average draught by sector as reported in Olmer et al. (2017) (see Table 13 on page 20). Weights were applied by vessel type based on fuel consumption data from the Faber and Xing (2020) (see Annex 1, Figure 4), since fuel consumption values by type are proportionally related to emissions. This weighted average provided a final estimate of 0.85. speed-power CF is defined as \((\text{speed}_{knots} / {\text{design\_speed}_{knots}}) ^3\), with the additional stipulation that this ratio should not exceed 1:
\[\text{Speed-power CF} = \begin{cases} 1 & \text{if } \frac{\text{speed}_{knots}}{\text{design\_speed}_{knots}} > 1, \\ \frac{\text{speed}_{knots}}{\text{design\_speed}_{knots}} & \text{otherwise} \end{cases}\]
In this equation, speed is the AIS-broadcast instantaneous speed when one hour or less has elapsed since the previous message (we assume activity within the past hour traveled at a similar speed). For longer gaps we use the implied speed, which is more reliable over longer intervals and is calculated as the distance from the last position divided by the hours since the last position. Design speed comes from a bespoke machine learning model developed by GFW to infer design speed using a model trained on registry-derived values(see Section 1.1.7).
As a last step, we ensure that the final load factor (the product of the above correction factors) does not exceed a value of 0.98, as recommended by Faber and Xing (2020) (see page 272).
\[\text{Load Factor} = \begin{cases} 0.98 & \text{if (Load Factor)} > 0.98, \\ \text{Load Factor} & \text{otherwise} \end{cases}\]
1.1.2.1.1 Adjustments for fishing vessels
For fishing vessels, we adjust the main engine load factor based on the relationships published by Coello et al. (2015) (and later used by Sala et al. (2018)).
- For fishing vessels of class
trawlersanddredge_fishing, when they are actively fishing we assign a main engine load factor of 0.75. The intuition is that for these vessel types, even if they are moving slowly, their engines can be exerting tremdeous power while they are actually fishing with depolyed gear. - For all fishing vessels, we limit the main engine load factor so that it falls between 0.2 and 0.9
1.1.2.1.2 Low-load emissions adjustments
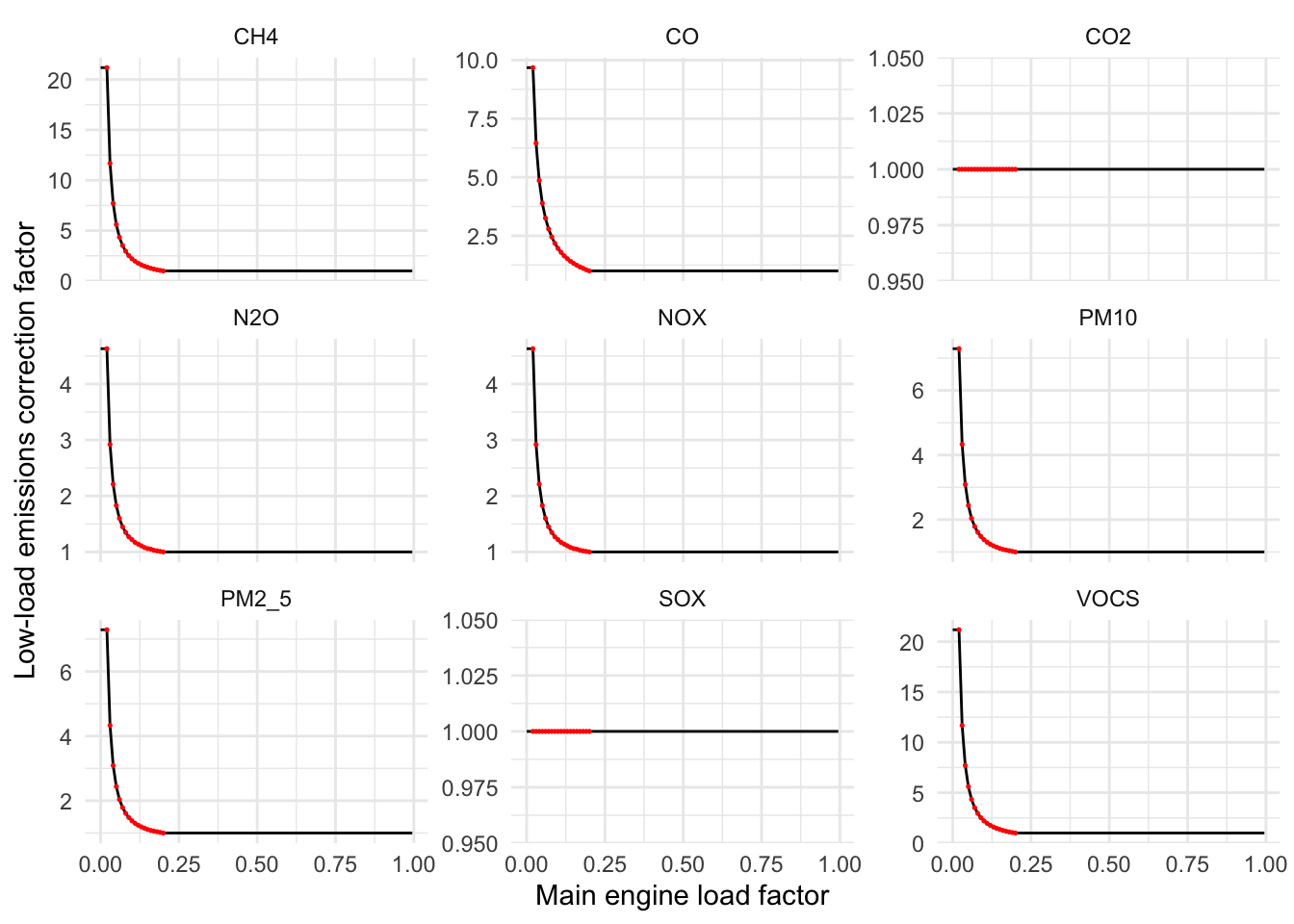
Additionally, for the main engine we apply low-load emissions correction factors based on the EPA’s 2020 Ports Emissions Inventory Guidance U.S. Environmental Protection Agency (2020) (which were the basis of the IMO Fourth GHG Report’s Table 20 @FourthIMOGHGStudy2020 ). Main engines operating during propulsion at very low loads below 20% operate inefficiently, and emit more of certain pollutants. Table 3.10 from the EPA report provides a lookup table of low-load emissions correction factors which vary based on the exact engine load and for each pollutant. Low-load correction factors are provided for a range from <=2% through >=20% in increments of 1%; if the engine load is <= 2%, it receives the correction factor corresponding to <=2%; if the load is greater than >=20%, it receives a correction factor of 1; if the load corresponds perfectly to a value in the table, it receives the corresponding correction correction factor; if the load falls between two values in the table, we linearly interpolate between those values. Following @FourthIMOGHGStudy2020, we do not apply any correction factors to CO2 or SOX.
In Figure 1.1 we can see what the low-load correction factors are for each pollutant in our analysis, each of which vary by main engine load (which falls between 0 and 1).
1.1.2.2 Main engine emissions factors
Main engine emissions for each pollutant are determined by multiplying each pollutant’s emissions factor (EF) by the main engine energy use. Main engine pollutant emission factors are derived from Appendix E in Olmer et al. (2017), and are assigned per vessel based on its engine type (oil/reciprocating, gas, or turbine), engine RPM, and year of build. For oil and reciprocating engines, RPM determines whether the vessel has a slow-speed (SSD, <300 RPM) or medium/high-speed (MSD/HSD) engine, which affects CO2, SOx, and PM factors. Year of build and RPM together determine the IMO NOx tier (pre-2000, Tier I 2000–2010, or Tier II 2011+), which sets the NOx factor; for medium-speed engines in Tiers I and II, the RPM-dependent formula from MARPOL Annex VI is used. For gas engines, factors are averaged across LNG fuel values. For turbine engines, factors are averaged across HFO, distillate, and ECA fuel columns, combining steam turbine and gas turbine rows where applicable. Where a vessel’s characteristics do not resolve to a single cell in the table, an average across the applicable cells is used.
1.1.3 Auxilliary engine and boiler
The model described in Faber and Xing (2020) assumes that while in service, a ship is operating in one of four defined phases: at berth, at anchor, maneuvering, or at sea.
For small vessels, we follow the recommendations from the 4th IMO study (page 68, Faber and Xing (2020)), where auxiliary engine power and boiler power are relative to main engine power. For larger vessels, aux_engine_power_kw and boiler_power_kw are defined based on vessel class and operational phase.
\[\text{Aux engine Energy Use}_{kWh} = \text{hours} \times \begin{cases} 0 & \text{if } \text{main\_engine\_power\_kw} \leq 150 \\ 0.05 \times \text{main\_engine\_power\_kw} & \text{if } \text{main\_engine\_power\_kw} \leq 500 \\ \text{aux\_engine\_power\_kw} & \text{otherwise} \end{cases}\]
\[\text{Boiler Energy Use}_{kWh} = \text{hours} \times \begin{cases} 0 & \text{if } \text{main\_engine\_power\_kw} \leq 150 \\ \text{boiler\_power\_kw} & \text{otherwise} \end{cases}\]
The inclusion of the four phases for larger vessels requires the use of Table 17 from the Faber and Xing (2020), including energy demand for the auxiliary engine and the boiler. However, this table expresses power demand based on vessel tonnage in different units. Since GFW has vessel size in GT, we needed to convert some of the values represented in DWT, TEU, and CBM to GT. Here, we present the approach followed to establish a direct size units relationship by vessel category.
1.1.3.1 DWT conversion
To establish the GT-DWT relationship, we used data containing both GT and DWT for each vessel. By assessing the relationship between these units, which mostly present linear relationships by vessel type, we defined a simple regression allowing us to derive conversion expressions with sufficient confidence from one unit to the other.
Such data was obtained through web scraping from open online sources, containing information for 464799 vessels on variables such as type, gt, dwt, length_m, beam_m, through which we could draw the size units relationship by vessel class.
Out of all vessel types, we only need to evaluate the tonnage relationship for several types in Table 17 from Faber and Xing (2020):
$ship_type
[1] "Bulk carrier" "Chemical tanker" "General cargo"
[4] "Oil tanker" "Other liquids tanker" "Refrigerated bulk"
[7] "Ro-Ro" In order to properly establish the size relationship, we need to group the categories from our dataset so they match the categories from Table 17. By doing so, we can evaluate each category’s relationship.
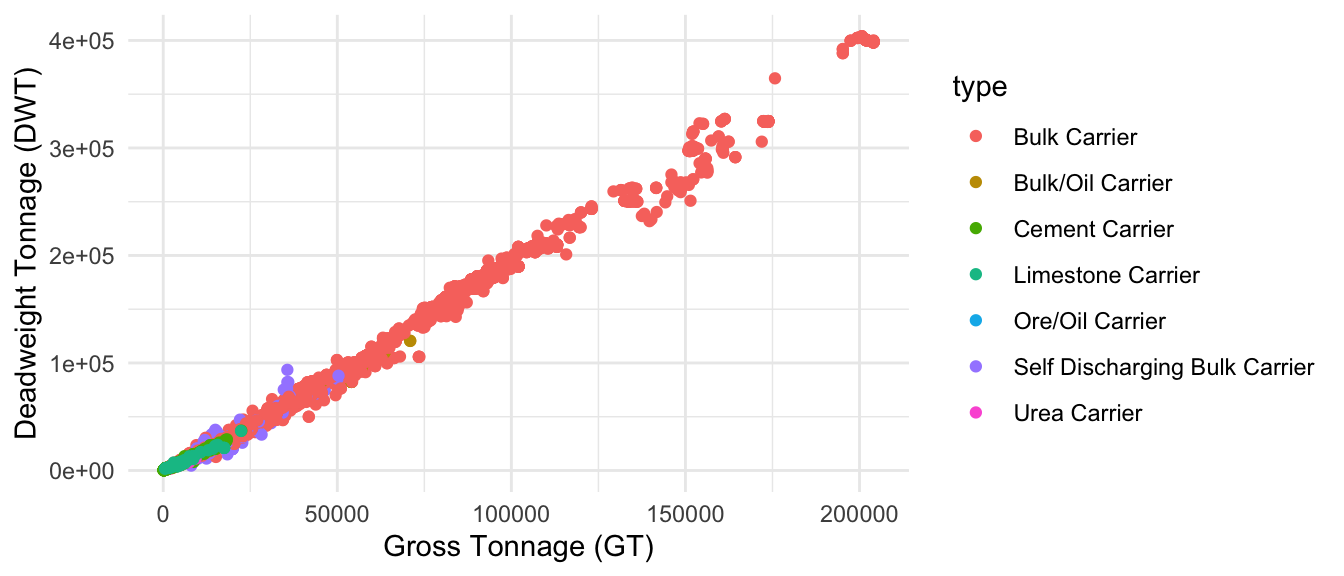
For instance, for Bulk carriers we have 7 categories which, according to Figure 1.2, present a linear relationship.
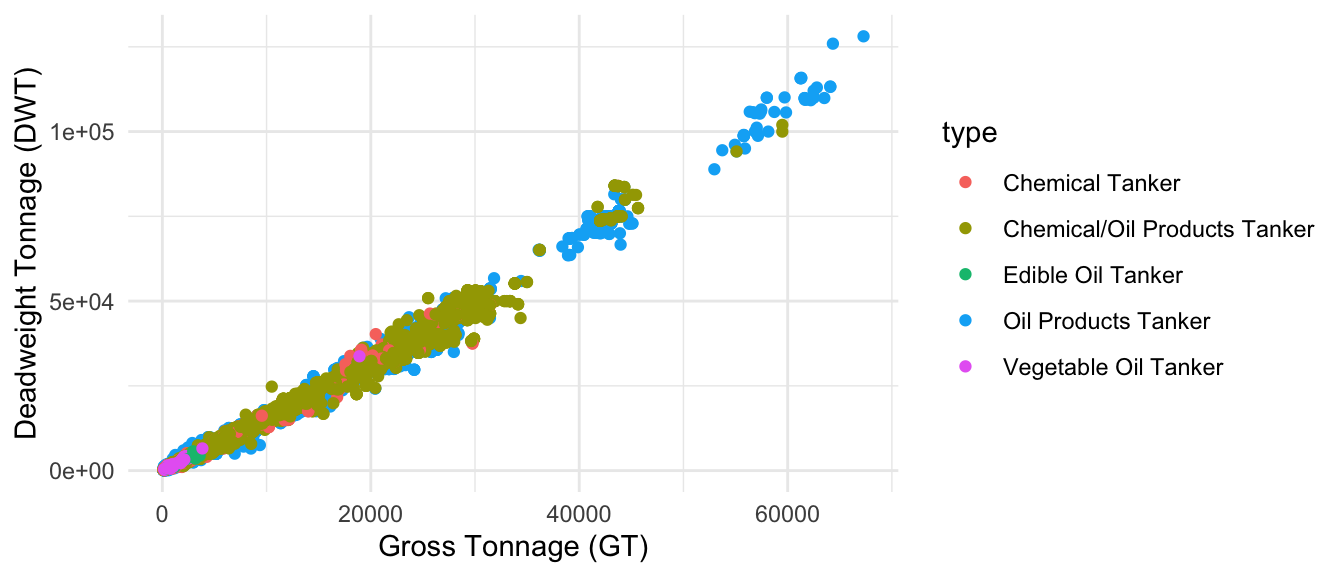
The same occurs for chemical tankers with 5 categories, as shown in Figure 1.3.
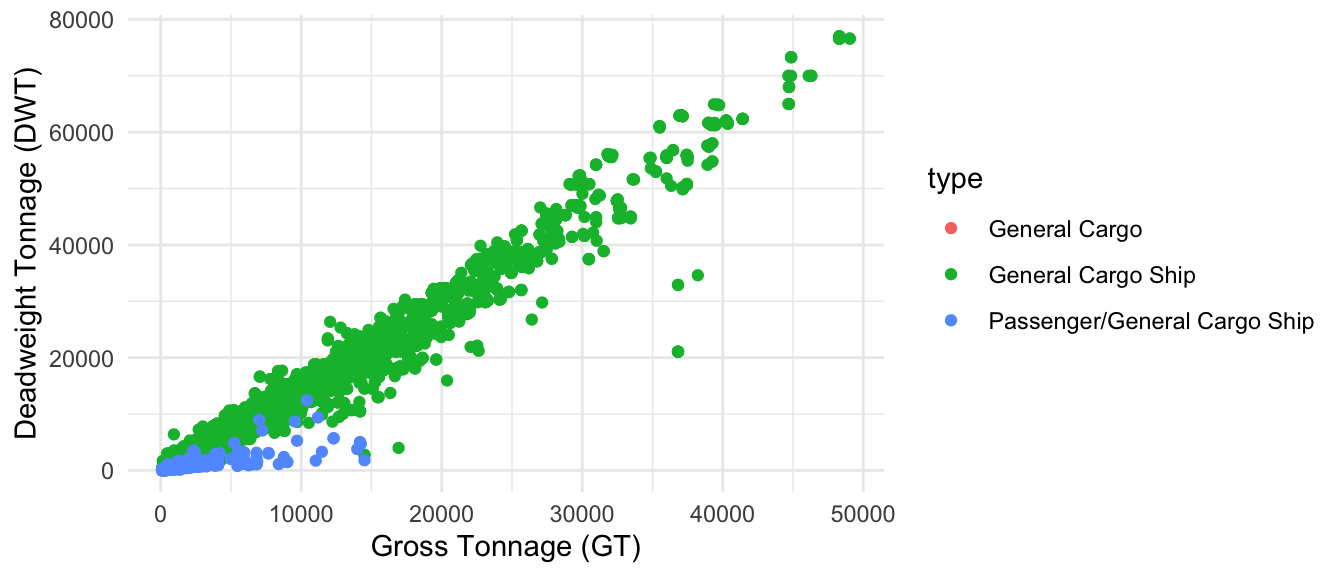
For general cargo, we have 3 categories. One of them, Passenger/General Cargo Ship, as seen in Figure 1.4, deviates from the linearity and may fall within the Ferry-pax only category from Table 17, so we will discart it.
Related to oil tankers, several vessel categories contain the label oil. However, most of them actually belong to chemical or bulk carriers. In this grouping, we will exclusively include crude oil tankers and bitumen Tankers.
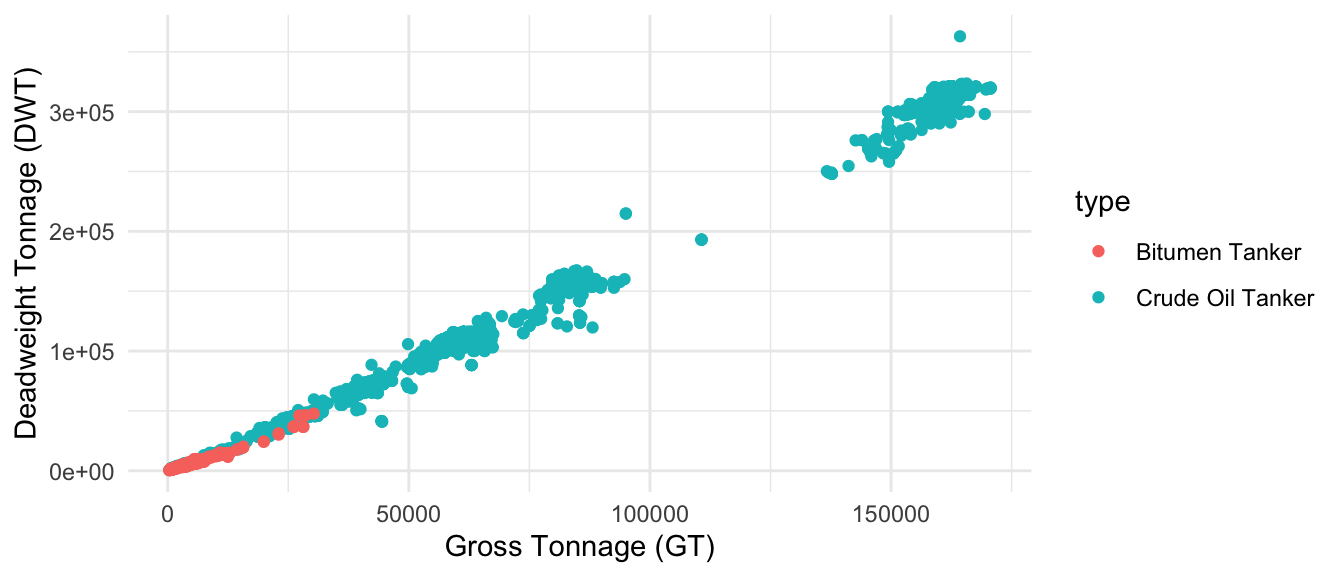
For the remaining liquid carriers, we will assign “Water Tanker”, “Wine Tanker” and “Molasses Tanker” from our table to the same category (Figure 1.6).
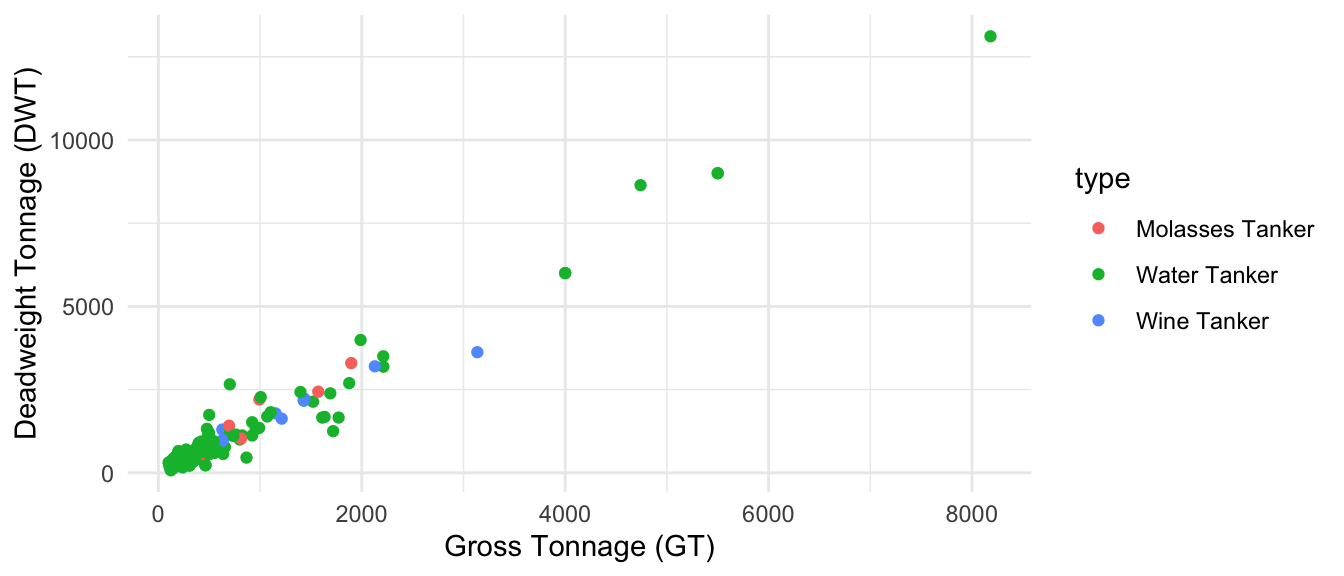
For refrigerated bulk, we have 2 categories, as shown in Figure 1.7.
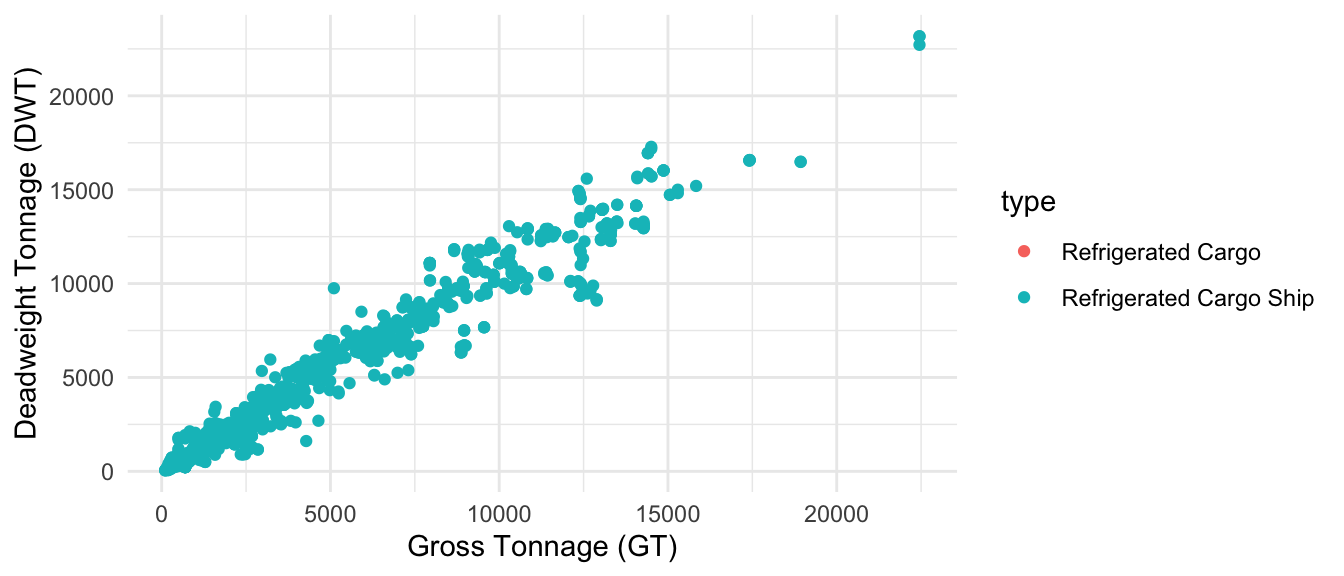
Lastly, for Ro ships, we have 3 categories, following distinct relationships as shown in Figure 1.8. Only Ro-Ro Cargo ships are the ones we are interested in, as the other two fall within the Ferry-RoPax category from Table 17.
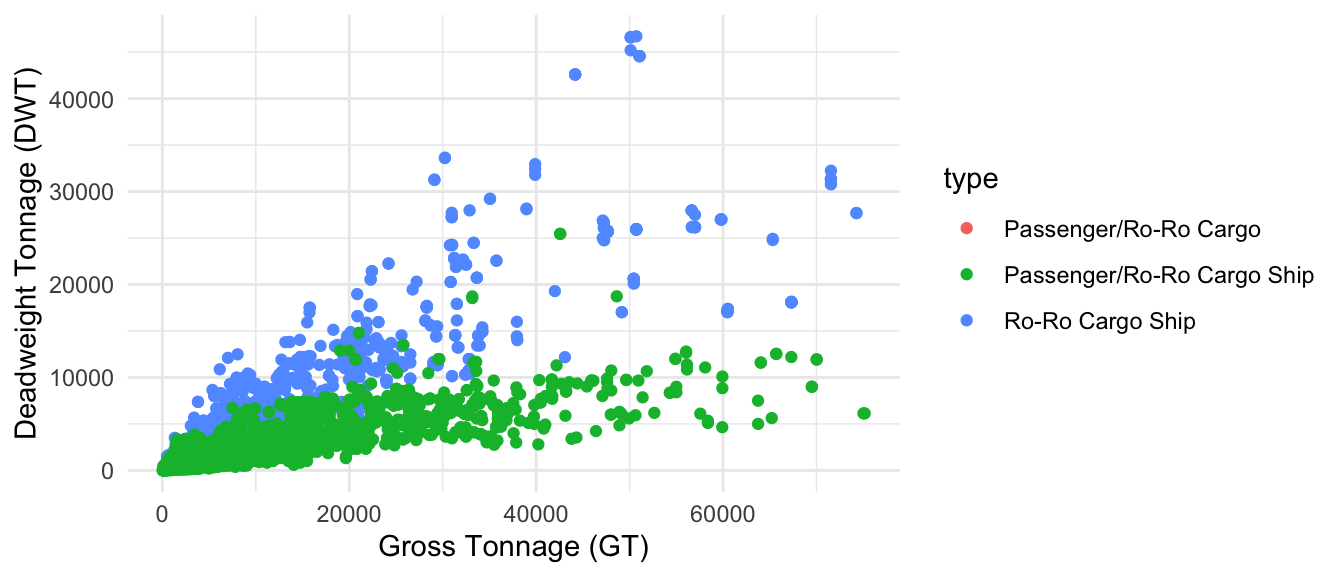
With the defined equivalences between groups from Faber and Xing (2020) and groups from our dataset described above, we update the original dataframe to adjust the regressions. By fitting gross tonnage (GT) based on deadweight tonnage (DWT) and grouped type, we obtain the expressions explaining the relationship between both size units per vessel type, along with the performance metrics summarized in Table Table 1.1. We save this expression in a lm model fit object and used it later to update table 17.
| r.squared | adj.r.squared | sigma | statistic | p.value | df | logLik | AIC | BIC | deviance | df.residual | nobs |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.9935724 | 0.9935717 | 2496.954 | 1325496 | 0 | 7 | -554797.7 | 1109613 | 1109694 | 374236342508 | 60024 | 60032 |
1.1.3.2 TEU conversion
TEU stands for Twenty-foot Equivalent Unit, which is a standard unit of measure used in the shipping industry to describe the capacity of container ships and terminals. One TEU represents the dimensions of a standard 20-foot long container. Therefore, TEU is used to quantify cargo capacity in terms of the number of 20-foot containers a vessel can carry. For example, a ship with a capacity of 10,000 TEU can carry 10,000 standard 20-foot containers.
For TEU, we obtain GT equivalents based on the design formulas for the calculation of key design vessel characteristics from Abramowski et al. (2018) as detailed below:
\[GT = -1097.4+11.049·TEU\]
1.1.3.3 CBM conversion
The size units of liquefied tankers represented as “CBM” refer to cubic meters (m³). This measurement indicates the volume capacity of the tankers, specifically how much liquefied gas (such as liquefied natural gas, LNG, or liquefied petroleum gas, LPG) they can carry.
For this unit conversion, we have not been able to find any large dataset to establish linear relationships, nor any publication defining expressions for unit conversion. The only available resource is the information from 23 vessels containing GT and CBM values, which allows to define a basic regression. This establishes the GT equivalence with intermediate to low confidence to update table 17 for gas tankers.
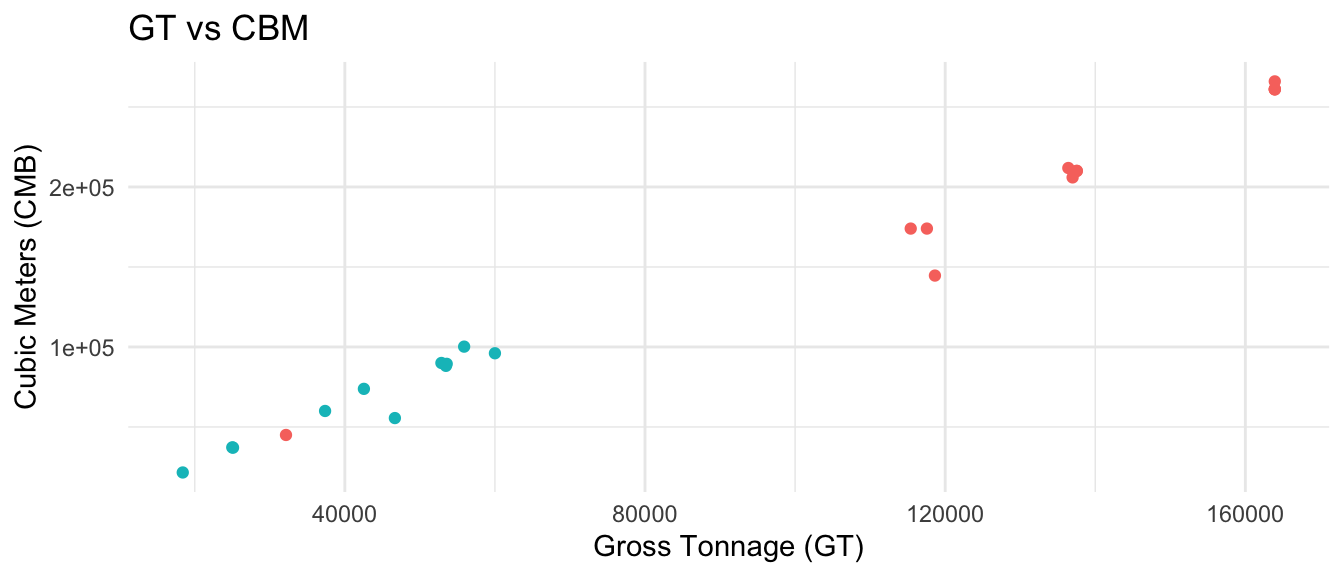
Here we see the model performance of GT as a function of CBM (Table 1.2).
| r.squared | adj.r.squared | sigma | statistic | p.value | df | logLik | AIC | BIC | deviance | df.residual | nobs |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.982426 | 0.9815891 | 7253.543 | 1173.945 | 0 | 1 | -236.0421 | 478.0841 | 481.4906 | 1104891522 | 21 | 23 |
1.1.3.4 Updating table 17
Once we defined the relationship between GT and the other size units for each vessel class, we updated Table 17 from (Table 1.3). This allows us to incorporate the auxiliary engine and boiler power outputs per vessel type and operational mode into our AIS-based model.
| ship_type | size_lower | size_upper | size_units | size_lower_gt | size_upper_gt |
|---|---|---|---|---|---|
| Bulk carrier | 0 | 9999 | dwt | 0.000 | 7738.351 |
| Bulk carrier | 10000 | 34999 | dwt | 7738.864 | 20567.005 |
| Bulk carrier | 35000 | 59999 | dwt | 20567.518 | 33395.658 |
| Bulk carrier | 60000 | 99999 | dwt | 33396.171 | 53921.504 |
| Bulk carrier | 100000 | 199999 | dwt | 53922.017 | 105236.119 |
| Bulk carrier | 200000 | NA | dwt | 105236.632 | NA |
1.1.3.5 Mapping GFW vessel types to IHS vessel types
GFW’s vessel classification algorithm classifies each vessel as a particular ship type. Many GFW vessel types were designed to match perfectly to IHS ship types (e.g., oil tankers, container cargos); in these cases, we can use the adjusted Table 17 directly as a lookup table. In some cases, a single GFW vessel type may patch to multiple IHS ship types (e.g., the GFW vessel type passenger could correspond to Ferry-RoPax, Ferry-Pax only, or Cruise). In these cases, we take an evenly-weighted average across the mutliple vessel types it could match to. Table 1.4 shows this mapping and the weights assigned. With this, we update proj_ocean_ghg.vessel_info_v* by including the corresponding boiler and auxiliary engine power demand considering vessel size and class for each of the four operational phases. These operational phases depend on the speed, distance to shore, and distance to port of each individual AIS, all of which is known from our core underlying GFW data. This can then be fed into the model to provide more accurate emission estimates.
| gfw_vessel_class | tb17_ship_type | weights |
|---|---|---|
| bunker | Oil tanker | 1.00 |
| cargo.bulk_carrier | Bulk carrier | 1.00 |
| cargo.container | Container | 1.00 |
| cargo.general | General cargo | 1.00 |
| cargo.refrigerated | Refrigerated bulk | 1.00 |
| cargo.ro_ro | Ro-Ro | 1.00 |
| container_reefer | Refrigerated bulk | 1.00 |
| dive_vessel | Service - other | 0.50 |
| dive_vessel | Offshore | 0.50 |
| dredge_fishing | Miscellaneous - fishing | 1.00 |
| dredge_non_fishing | Service - other | 0.50 |
| drifting_longlines | Miscellaneous - fishing | 1.00 |
| driftnets | Miscellaneous - fishing | 1.00 |
| fish_factory | Miscellaneous - fishing | 1.00 |
| other_fishing | Miscellaneous - fishing | 1.00 |
| other_not_fishing | Miscellaneous - other | 0.50 |
| other_not_fishing | Service - other | 0.50 |
| other_purse_seines | Miscellaneous - fishing | 1.00 |
| other_seines | Miscellaneous - fishing | 1.00 |
| passenger | Ferry-RoPax | 0.33 |
| passenger | Ferry-pax only | 0.33 |
| passenger | Cruise | 0.33 |
| patrol_vessel | Service - other | 1.00 |
| pole_and_line | Miscellaneous - fishing | 1.00 |
| pots_and_traps | Miscellaneous - fishing | 1.00 |
| research | Service - other | 0.50 |
| research | Offshore | 0.50 |
| seismic_vessel | Service - other | 0.50 |
| seismic_vessel | Offshore | 0.50 |
| set_gillnets | Miscellaneous - fishing | 1.00 |
| set_longlines | Miscellaneous - fishing | 1.00 |
| specialized_reefer | Refrigerated bulk | 1.00 |
| squid_jigger | Miscellaneous - fishing | 1.00 |
| supply_vessel | Service - other | 0.50 |
| supply_vessel | Offshore | 0.50 |
| tanker.chemical | Chemical tanker | 1.00 |
| tanker.liquefied_gas | Liquefied gas tanker | 1.00 |
| tanker.oil | Oil tanker | 1.00 |
| tanker.other | Other liquids tanker | 1.00 |
| trawlers | Miscellaneous - fishing | 1.00 |
| trollers | Miscellaneous - fishing | 1.00 |
| tug | Service - tug | 1.00 |
| tuna_purse_seines | Miscellaneous - fishing | 1.00 |
| well_boat | Service - other | 1.00 |
1.1.3.6 Auxilliary engine and boiler emissions factors
Auxiliary engine and boiler emissions are determined by multiplying each pollutant’s emissions factor by the auxiliary engine or boiler energy use. Auxiliary engine emissions factors are derived from Appendix G and boiler emissions factors from Appendix H of Olmer et al. (2017), and are assigned per vessel based on its engine type and, for auxiliary engines, its NOx tier.
For auxiliary engines, oil and reciprocating engine factors are averaged across HFO, distillate, and 2015+ ECA fuel columns. NOx factors additionally depend on the vessel’s engine tier, determined by year of build and engine RPM: pre-2000 vessels receive a single factor, while Tier I (2000–2010) and Tier II (2011+) vessels use RPM-dependent factors, with the MARPOL Annex VI formula applied for medium-speed engines. Gas engine factors are averaged across LNG values. Turbine engines are assigned zero for all pollutants, since turbine-propelled vessels use their turbines for auxiliary power and heat. When a vessel’s characteristics do not resolve to a single cell in the table, an average value calculated from across the applicable cells is used.
For boilers, the same engine-type-based approach is used (oil/ reciprocating averaged across HFO, distillate, and ECA fuel columns; gas averaged across LNG values; turbine set to zero), but boiler factors do not vary by NOx tier or RPM.
\[\text{Aux engine emissions}_{g} = \text{hours} \times \begin{cases} \text{aux\_at\_berth}_{kW} \\ \text{aux\_at\_anchor}_{kW} \\ \text{aux\_maneuvering}_{kW} \\ \text{aux\_at\_sea}_{kW} \end{cases} \times \text{Aux emissions factor}_{g/kWh}\]
\(\text{Boiler emissions}_{g} = \text{hours} \times \begin{cases} \text{boiler\_at\_berth}_{kW} \\ \text{boiler\_at\_anchor}_{kW} \\ \text{boiler\_maneuvering}_{kW} \\ \text{boiler\_at\_sea}_{kW} \end{cases} \times \text{Boiler emissions factor}_{g/kWh}\)$
1.1.4 Total emissions
Finally, using the factors above, we estimate total emissions by multiplying Main Engine Energy Use, Aux Engine Energy Use and Boiler Energy Use by their respective emissions factors. We then sum the three values to get the total emission estimate.
\[\text{Total Emissions}_{ CO_2, NO_X, ...} =\text{Main Engine Emissions}_{ CO_2, NO_X, ...} + \text{Aux Engine Emissions}_{ CO_2, NO_X, ...} + \text{Boiler Emissions}_{ CO_2, NO_X, ...}\]
1.1.5 Additional pollutants
For three additional pollutants (PM2.5, PM10, and VOCs), we scale each engine’s CO2 emissions factor (main, auxiliary, and boiler) by the conversion factors in the following table. These conversion factors were provided by OceanMind, so our methodology is consistent with their approach for these pollutants (detailed in Mayes et al. (2024)). They are based on Table 27 from the 4th IMO report (Faber and Xing (2020)), which gives emissions factors for each pollutant and fuel type (kg of pollutant per tonne of fuel consumed) for Heavy Fuel Oils (HFO), Liquefied Natural Gas (LNG), Marine Diesel Oil (MDO), and methanol. Using the 2018 factors, the PM2.5, PM10, and VOCs emissions factors were each divided by the corresponding CO2 emissions factor, by fuel type. These ratios were then combined into a weighted average for each pollutant, weighted by the share of vessels using each fuel type (the 2018 values from Table 34 of the IMO report). This gives the factors we use directly:
| gPM2.5/gCO2 | gPM10/gCO2 | gVOCS/gCO2 |
|---|---|---|
| 0.001598 | 0.001738 | 0.000933 |
1.1.6 Low sulfur fuel emissions correction factors for post-2020 data
Starting on January 1, 2020, the IMO required lower sulfur content fuel (0.5%, instead of the higher 2.5% that was typical for HDO prior to 2020). For data >= 2020-01-01, we therefore apply a new correction factor for SOX and PM to account for this lower sulfur content fuel.
For SOX: based on equation 15 (p. 74) of the 4th IMO report, the SOX emissions factor scales linearly with sulfur percentage content. For the pre-2020 SOX EF, we use Table E from the 2017 ICCT study, and take the average of the HFO value which is based on a 2.5% sulfur content (which is consistent the HFO row in Table 22 from the 4th IMO report). Assuming the sulfur content drops from 2.5% to 0.5% starting in 2020, this means an 80% drop in sulfur content, and an 80% drop in the sulfur EF. This 80% is consistent with several studies that looked the the impact this new requirement had on global sulfur emissions (@yuan2024abrupt, @yoshioka2024warming). So for the >= 2020-01-01 SOX EF, we can simply multiply our current < 2020-01-01 EF by 0.2. We can do this across the three main, aux, and boiler EFs.
For PM, PM2.5, and PM10: Equation 16 (p.74) of the 4th IMO report defines the PM10 EF relationship to sulfur content for HFO. This equation isn’t a perfect scalar factor like SOX, and depends on SFCi and has a constant. Based on Table 19 (p. 70) from the 4th IMO report, the average SFCi of HDO is 185 g/kWH (175 for SSD, 185 for MSD, and 195 for HSD). If we plug this into Equation 16, we get a < 2020-01-01 EF of 73.38 assuming a sulfur content of 2.5% (1.35+185*7*.02247*(2.5-.0246)) Assuming a post-2020 sulfur content of 0.5%, we get a >= 2020-01-01 EF of 15.18 (1.35+185*7*.02247*(0.5-.0246) ). The ratio of these two is 15.18/73.38 = 0.206, which is almost exactly the ratio for sulfur. So for the >= 2020-01-01 EFs for PM PM10 and PM2.5, we simply multiply our current < 2020-01-01 EF by 0.206. We can do this across the three main, aux, and boiler EFs of each pollutant.
1.1.7 Data
1.1.7.1 Individual AIS messages
For our individual AIS messages (pings) dataset, we leverage the latest-and-greatest version of the GFW’s AIS pipeline, Version 4. This is one of the GFW’s core internal datasets. This process automates the parsing, cleaning, augmenting, and publishing of raw AIS data (Kroodsma et al. (2018)). This table provides data from 2012 to present. Using this table as our starting point, we are able to estimate emissions from all analyzed pollutants for every single AIS message. These ping-level emissions can then later be aggregated however desired (e.g., by vessel, by voyage, by destination or arrival port, by time, by space, etc.)
Variables of interest within this table include the following:
ssvid: source specific vessel id; MMSI for AIS
hours: time since the previous position in the segmentspeed_knots: speed (knots) from AIS messageimplied_speed_knots: distance from last position divided by hours since last position
meters_to_prev: distance (meters) to the previous point in the segmentdistance_from_shore_m: distance from shore (meters)distance_from_port_m: distance from port (meters)neural net score: The score is 1 if the neural net thinks this is a fishing position.night_loitering: 1 if theseg_idof every message of a squid_jigger that is at night and not moving, 0 if not.
To minimize noisy data, we apply several filters to the AIS messages:
- We only include messages within valid segments (
good_seginpipe_ais_v4_published.segs_activity) and exclude daily segments that overlap with one another (those inoverlap_segs_daily_v20260109). - To guard against GNSS interference, we drop messages whose reported speed exceeds twice the vessel’s design speed, and we keep only messages that fall in ocean (non-inland) raster cells, which removes positions that erroneously place a vessel on land.
1.1.7.2 Vessel characteristics
Vessel characteristics also represent another one of the core GFW datasets. These tables provides metadata for all vessels contained within GFW, organized by MMSI. The information for each vessel includes: 1) official registry information, when available (Park et al. (2023)); or 2) algorithm-derived vessel characteristics such as vessel class, engine power, and gross tonnage, when registry data are not available (Kroodsma et al. (2018)). Additionally, new not-yet-published vessel characteristic algorithms have been developed to infer specific cargo and tanker vessel class; design speed; engine type (oil, gas, or turbine); year of build; and engine speed. The GFW vessel characteristics database leverages extensive work that has been done to scrape and aggregate many publicly available vessel registries (Park et al. (2023)). Note that since we are currently using a cutting edge version of this database that infers previously-unavailable vessel characteristics, this differs from the official Version 4 of the pipeline that is publicly available from GFW.
As part of this, we are leveraging two brand new cargo and tanker vessel type classification sub-models developed by GFW that build off the general vessel classification algorithm for low information vessels (i.e., those that don’t have known registry information). We can now differentiate many vessels that were previously lumped together as an undifferentiated cargo vessel type into the specific categories of bulk_carrier, container, general, refrigerated, and ro_ro. We can also now differentiate many vessels that were previously lumped together as an undifferentiated tanker vessel type into the specific categories of oil, chemical, liquefied gas, and other liquids. These classes now align perfectly with the IMO cargo and tanker vessel class types, allowing us to more accurately assign auxiliary engine power and boiler power for these vessel classes using the IMO methodology. These new models each leverage a random forest that is trained on information on port visit patterns vessels with known IMO cargo or tanker vessel class types. Sequences of port visits are converted into usable model features by implementing a Word2Vec model that transforms them into numeric arrays called embeddings. Additionally, each model also uses model features based on vessel activity including port hours, average distance from shore, and average speed. This allows us to more accurately classify cargo or tanker vessel types by looking at the most common IMO known vessel types that use the same ports. The cargo sub-model achieves am F1 weighted average score of 0.89, while the tanker sub-model achieves am F1 weighted average score of 0.87.
Variables of interest from proj_ocean_ghg.vi_ssvid_v20260401 (the core GFW pipeline 4 vessel characteristics table) include the following:
ssvid: source specific vessel id; MMSI for AISbest.flag: best flag state (ISO3) for the vesselactivity.active_hours: hours the vessel was broadcasting AIS and moving more than 0.1 knots. If desired, we can use this as a filter; vessels with < 24 hours of active hours have very limited data from which to calculate emissions from.registry_info.registries_listed: vessel registries the vessel is listed onregistry_info.best_known_shipname: best known shipname for the vessel from registriesais_identity.n_shipname_mostcommon.value: the most common normalized shipname broadcasted by this vesselregistry_info.best_known_callsign: best known callsign for vessel from registriesais_identity.n_callsign_mostcommon.value: the most common normalized callsign broadcasted by this vesselregistry_info.best_known_imo imo_registry: best known IMO number for the vessel from registriesais_identity.n_imo_mostcommon.value imo_ais: the most common normalized IMO number broadcasted by this vesseloffsetting: true if this vessel has been seen with an offset position at some point between 2012 and 2019 (this should be FALSE; if it is TRUE, it can be used as a filter to remove potentially erroneous/noisy vessels)overlap_hours_multinames: the total numbers of hours of overlap between two segments where, over the time period of the two segments that overlap (including the non-overlapping time of the segments), the vessel broadcast two or more normalized name, where each normalized name was broadcast at least 10 or more times. That is a bit complicated, but the goal is to identify overlapping segments where there were likely more than one identity. (this should be 0; if it is > 0, it can be used as a filter to remove potentially erroneous/noisy vessels)
Variables of interest from proj_ocean_ghg.cargo_subtype_and_characteristics_v20260601 (the combined vessel characteristics and cargo/tanker sub-classification table developed for this project) include the following:
ssvid: source specific vessel id; MMSI for AISvessel_class: inferred vessel class for the vesselcargo_tanker_subclass: cargo or tanker sub-class from the new cargo and tanker vessel specific classification sub-model, where availablecargo_tanker_subclass_low_confidence: lower-confidence cargo or tanker sub-class prediction, used as a fallback when the higher-confidence prediction is not availablevessel_class_low_confidence: lower-confidence vessel class prediction, used as an additional fallbackengine_power_kw: best engine power (kilowatts) for the vesseltonnage_gt: best tonnage (gross tons) for the vessellength_m: best length (meters) for the vesselmax_speed_kn: best maximum speed (i.e., design speed) (knots) for the vesselengine_type: engine type for the vesselfuel_type: fuel type for the vesselRPM: engine RPM for the vesselyear_of_build: year the vessel was built
In the SQL query (vessel_info.sql), the final vessel class is determined using the highest resolution classification available, following this hierarchy: COALESCE(cargo_tanker_subclass, cargo_tanker_subclass_low_confidence, vessel_class_low_confidence, vessel_class).
There are currently 864,738 AIS-broadcasting vessels in the GFW dataset (this number excludes any AIS transponders which are labeled as fishing gear, helicopters, or submarines). Of these, we are able to estimate emissions 864,768 unique active vessels over our entire time period. Of these, 839,223 (97%) are ‘low-information’ vessels without an IMO number.
1.1.7.3 Voyages
Again leveraging Version 4 of the pipeline, GFW’s voyages table contains information for port-to-port voyages made by vessels. This table leverages extensive work done by the GFW team to: 1) define ports, 2) determine when vessels arrive at or depart from a port, and 3) determine voyages that are define by a port departure and a port arrival (Watch (2021)).
To define ports, specific anchorages are first identified by using the AIS data to find S2 cell locations where at least 20 unique vessels remained stationary at some point since 2012 (where ‘stationary’ is defined as moving less than 0.5km within a 12-hour period). Once these initial anchorage locations have been identified, anchorages within 4km of each other are grouped into ports. In this way, a single port may contain multiple anchorages within that port. Port names are then assigned to each of these locations spatially according to the following heirarchy:
- World Port Index
- GeoNames 1000 database that describes all settlements globally that have a population of at least 1,000 people
- The top destination reported in AIS messages of stationary vessels that defined that anchorage
- Contributed names and regional port databases
Once ports have been identified, heuristics are used to identify port entries and exits:
A vessel enters port when it comes within 3 kilometers of an anchorage point and exits port when it is outside 4 kilometers of the anchorage point. We use different threshold distances to avoid situations where a vessel continuously enters and exits port. This situation is still common, however, as vessels travel along coastlines and repeatedly come within close proximity to numerous anchorages. To distinguish actual port visits from coastal transits, we further identify when a vessel appears to stop at a given port. The vessel is considered to have “stopped” at port if its speed drops below 0.2 knots, and this port stop ends when the speed rises above 0.5 knots. AIS is often switched off when a vessel enters port, and it is turned back on when it leaves. As a result, we track port “gaps,” where a vessel that has entered port does not broadcast on AIS for at least four hours. Port stops and port gaps are behaviors indicating that a vessel visited a port for a specific reason and/or engaged in some activity while at the port, such as landing catch or exchanging supplies and crew. We can then allocate the at-sea activity of vessels to individual voyages between port visits.
Once these port entries and exits have been identified, voyages can simply be defined as all activity between those port events. In this way, individual AIS message (and its associated emissions) can be assigned to a voyage.
Variables of interest within this table include the following:
ssvid: source specific vessel id; MMSI for AIStrip_id: A unique identifier for the trip generated by the ssvid, vesssel-id and the exit time of starting visittrip_start: The initial timestamp of the voyage, when the vessel leaves porttrip_end: The final timestamp of the voyage, when the vessel reaches porttrip_start_anchorage_id: The id of the anchorage where the voyage startstrip_end_anchorage_id: The id of the anchorage where the voyage ends
For quality control purposes, we filter this dataset to just those voyages with a confidence level of 3 or 4.
Further information of the starting and ending anchorages can be obtained by joining this table to GFW’s anchorage table, which includes the following:
anchorage_id: The id of the anchoragelabel: Port nameiso3: Port ISO3 codelat: latitude of the anchoragelon: longitude of the anchorage
In summary, from 2015-01-01 to 2026-05-31, we have 164,628,420 unique voyages across 789,738 unique vessels. These trips visited 14,702 unique ports across 209 unique countries.
1.1.7.4 Port visits
Again leveraging Version 4 of the pipeline, we use GFW’s port visits table. Port visits are determinede using the same methods as describe above for assigning voyages. Variables of interest within this table include the following:
ssvid: source specific vessel id; MMSI for AISvisit_id: Unique ID for this visitstart_timestamp: timestamp at which vessel crossed into the anchorageend_timestamp: timestamp at which vessel crossed out the anchoragestart_anchorage_id:anchorage_idof anchorage where vessel entered portend_anchorage_id:anchorage_idof anchorage where vessel exited portconfidence: How confident are we that this is a real visit based on components of the visits: 1 -> no stop or gap; only an entry and/or exit 2 -> only stop and/or gap; no entry or exit 3 -> port entry or exit with stop and/or gap 4 -> port entry and exit with stop and/or gap
For quality control purposes, we filter this dataset to just those port visits with a confidence level of 3 or 4. We also only filter to those port visits where the starting and ending port label are the same.
As with the voyages dataset, for information of the port starting and ending anchorages can be obtained by joining this table to GFW’s anchorage table. Variables of interest within this table include the following:
anchorage_id: The id of the anchoragelabel: Port nameiso3: Port ISO3 codelat: latitude of the anchoragelon: longitude of the anchorage
Note again that since a single port can have multiple anchorages, it is possible that a single port visit has different starting and ending anchorages, and therefore lat/lon locations.
In summary, from 2015-01-01 to 2026-05-31, we have 121,958,014 unique port visits across 785,693 unique vessels. These port visits trips occurred in 14,522 unique ports across 209 unique countries.
1.1.8 Areas of potential model refinement
We have identified a number of areas for potential model refinement. They are all related to the need for improved vessel characteristics metadata:
- Vessel classification: Continue to align GFW vessel classes with IHS vessel classes: Some GFW and IHS vessel classes are currently categorized slightly differently (for example, those related to passenger vessels), meaning that we need to translate and aggregate certain information that is provided by the ICCT and IMO for IHS vessel classes (i.e., auxiliary engine power by vessel type) into the GFW vessel classes.
- Vessel size units conversion: The inclusion of the four operational phases requires the use of auxiliary engine and boiler energy demand values by vessel size. As described earlier, this entails setting unit conversion expressions that can be refined to better capture energy demand, especially those for TEU, DWT, and CBM conversion.
- Draft correction factor: Currently, we use the same draft correction factor for all vessels. This single draft correction factor is currently an average of vessel class-specific correction factors, weighted by the total emissions by each vessel class. Future model iterations may want to use vessel class-specific draft factors.
1.2 Results
In this section, we provide some high-level results from our emissions model.
1.2.1 Time series trends
1.2.1.1 Number of vessels
First, we look at total global number of active vessels per year from 2017 to 2025 (Figure 1.10, Table 1.5).
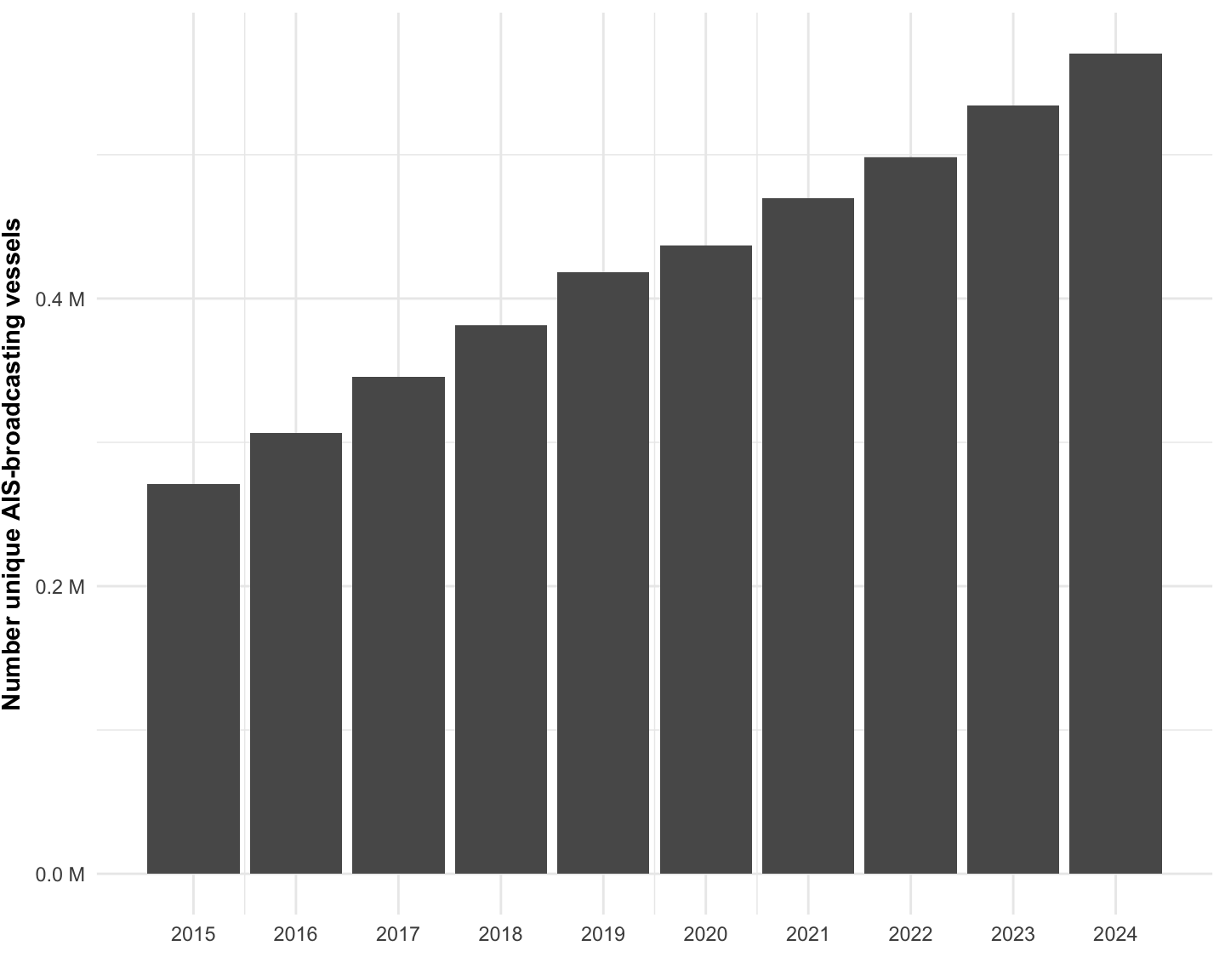
| vessel_class | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 | 2025 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| passenger | 70,144 | 84,327 | 100,671 | 117,297 | 133,751 | 141,796 | 164,332 | 182,153 | 198,456 | 217,317 | 232,317 |
| trawlers | 45,975 | 52,261 | 58,153 | 63,958 | 66,958 | 68,478 | 71,900 | 73,993 | 79,132 | 79,878 | 81,053 |
| cargo.general | 41,724 | 46,884 | 50,218 | 51,316 | 55,626 | 58,258 | 57,265 | 54,440 | 54,811 | 55,692 | 55,194 |
| tug | 25,764 | 28,061 | 31,048 | 32,382 | 35,320 | 37,223 | 38,537 | 38,794 | 40,393 | 42,973 | 44,371 |
| cargo.bulk_carrier | 11,972 | 12,670 | 13,105 | 13,186 | 13,688 | 14,204 | 14,897 | 15,518 | 16,025 | 16,793 | 17,112 |
| driftnets | 7,927 | 9,356 | 10,398 | 11,550 | 12,340 | 12,634 | 13,593 | 14,640 | 16,314 | 16,193 | 16,150 |
| tanker.oil | 9,988 | 10,200 | 10,581 | 11,090 | 11,187 | 11,314 | 11,513 | 11,809 | 11,949 | 12,736 | 13,468 |
| drifting_longlines | 3,104 | 3,837 | 4,646 | 5,236 | 5,873 | 6,656 | 8,283 | 9,989 | 10,762 | 11,374 | 11,874 |
| cargo.container | 5,098 | 5,141 | 5,322 | 5,314 | 5,410 | 5,460 | 5,803 | 5,927 | 6,323 | 6,849 | 7,213 |
| tanker.chemical | 4,730 | 4,928 | 5,099 | 5,242 | 5,429 | 5,468 | 5,631 | 5,846 | 5,942 | 6,131 | 6,518 |
| set_gillnets | 2,291 | 2,761 | 3,246 | 3,701 | 3,990 | 4,276 | 4,770 | 4,826 | 5,457 | 5,872 | 6,446 |
| supply_vessel | 4,289 | 4,086 | 3,929 | 3,991 | 4,092 | 4,052 | 4,038 | 4,251 | 4,398 | 4,549 | 4,583 |
| patrol_vessel | 2,272 | 2,470 | 2,758 | 3,026 | 3,140 | 3,315 | 3,515 | 3,848 | 4,160 | 4,385 | 4,560 |
| cargo.ro_ro | 2,387 | 2,505 | 2,600 | 2,746 | 3,009 | 3,089 | 3,214 | 3,513 | 3,727 | 4,045 | 4,291 |
| bunker | 1,837 | 2,120 | 2,322 | 2,437 | 2,664 | 2,774 | 2,603 | 2,499 | 3,476 | 3,719 | 3,782 |
| squid_jigger | 608 | 684 | 754 | 864 | 1,009 | 1,873 | 2,320 | 2,585 | 2,782 | 2,982 | 3,004 |
| dredge_non_fishing | 1,818 | 1,968 | 2,197 | 2,292 | 2,308 | 2,383 | 2,450 | 2,502 | 2,618 | 2,706 | 2,850 |
| pots_and_traps | 1,102 | 1,362 | 1,630 | 1,865 | 2,019 | 2,116 | 2,187 | 2,203 | 2,228 | 2,252 | 2,283 |
| tanker.liquefied_gas | 1,310 | 1,379 | 1,460 | 1,560 | 1,589 | 1,664 | 1,773 | 1,843 | 1,876 | 2,041 | 2,160 |
| other_not_fishing | 1,088 | 1,072 | 1,105 | 1,131 | 1,192 | 1,252 | 1,369 | 1,437 | 1,535 | 1,626 | 1,643 |
| pole_and_line | 451 | 539 | 614 | 697 | 758 | 842 | 967 | 1,058 | 1,186 | 1,308 | 1,372 |
| seismic_vessel | 1,086 | 1,095 | 1,087 | 1,114 | 1,120 | 1,121 | 1,130 | 1,155 | 1,229 | 1,249 | 1,292 |
| set_longlines | 423 | 448 | 471 | 492 | 545 | 597 | 655 | 712 | 763 | 810 | 816 |
| other_fishing | 8 | 5 | 17 | 38 | 46 | 118 | 232 | 371 | 501 | 629 | 714 |
| tuna_purse_seines | 424 | 514 | 549 | 569 | 621 | 641 | 660 | 677 | 669 | 671 | 674 |
| specialized_reefer | 518 | 516 | 530 | 531 | 530 | 504 | 498 | 479 | 471 | 463 | 446 |
| dive_vessel | 323 | 354 | 349 | 365 | 375 | 366 | 370 | 366 | 368 | 363 | 348 |
| trollers | 150 | 181 | 211 | 243 | 276 | 285 | 293 | 304 | 308 | 302 | 309 |
| dredge_fishing | 237 | 249 | 245 | 240 | 243 | 259 | 249 | 252 | 250 | 265 | 258 |
| other_seines | 154 | 160 | 168 | 171 | 175 | 174 | 180 | 176 | 177 | 173 | 171 |
| other_purse_seines | 82 | 85 | 91 | 93 | 96 | 100 | 111 | 109 | 115 | 124 | 125 |
| cargo.refrigerated | 136 | 161 | 192 | 207 | 202 | 189 | 178 | 139 | 127 | 122 | 120 |
| well_boat | 71 | 79 | 84 | 91 | 91 | 94 | 96 | 100 | 98 | 98 | 97 |
| container_reefer | 105 | 102 | 104 | 104 | 98 | 93 | 91 | 88 | 85 | 80 | 79 |
| research | 46 | 52 | 55 | 59 | 63 | 60 | 63 | 63 | 63 | 65 | 68 |
| tanker.other | 30 | 29 | 27 | 28 | 30 | 30 | 29 | 31 | 32 | 33 | 35 |
| fish_factory | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | NA |
1.2.1.2 Voyages
Next, we summarize the number of voyages, globally, for vessels included in our analysis from 2017 to 2025 (Figure 1.11, Table 1.6).
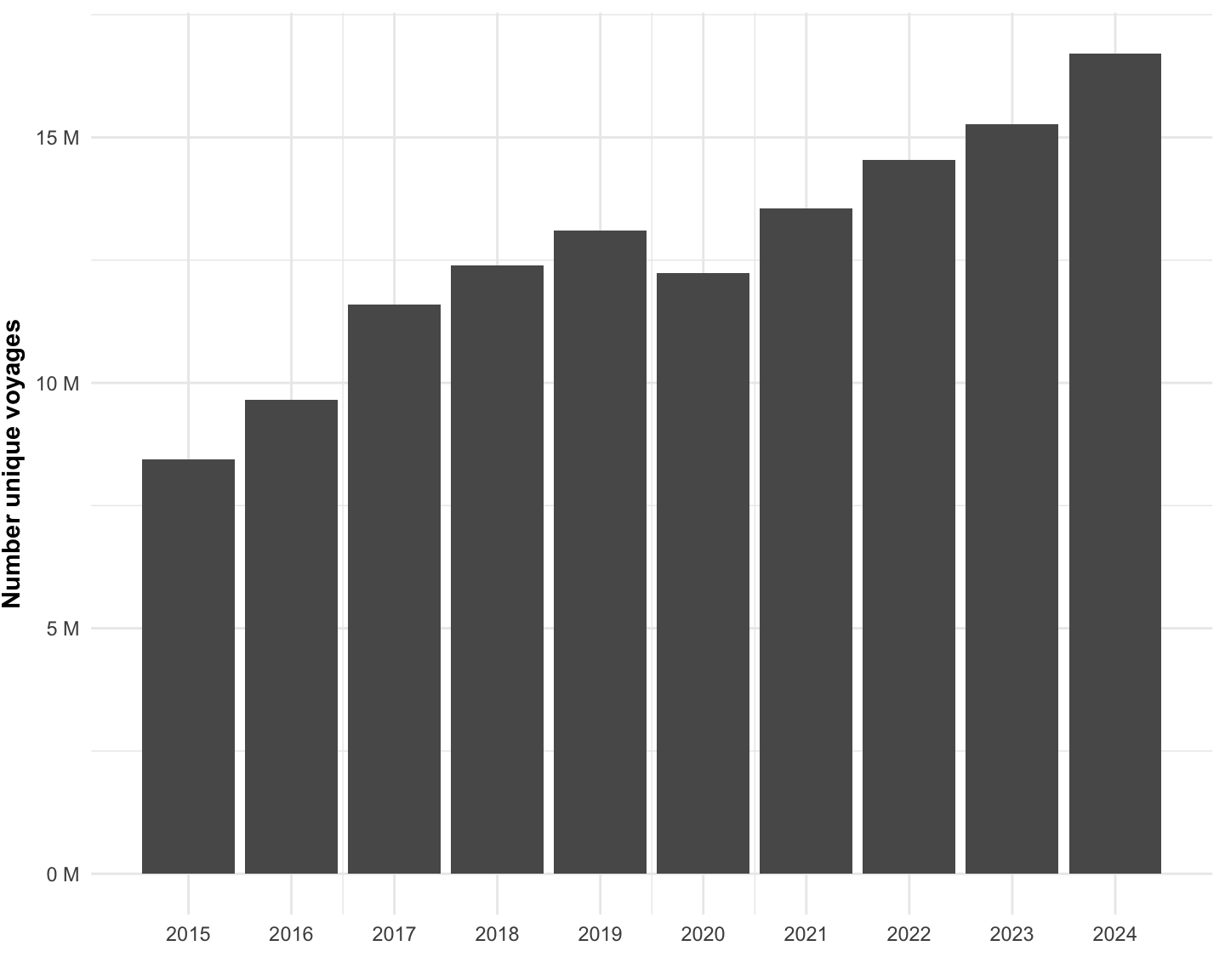
| year | n_unique_events |
|---|---|
| 2015 | 8,438,108 |
| 2016 | 9,703,854 |
| 2017 | 11,618,492 |
| 2018 | 12,366,531 |
| 2019 | 13,077,003 |
| 2020 | 12,168,081 |
| 2021 | 13,443,056 |
| 2022 | 14,487,915 |
| 2023 | 15,267,205 |
| 2024 | 16,686,430 |
| 2025 | 17,826,395 |
1.2.1.3 Port visits
Here we summarize the time series trend of the number of port visits, globally, for the vessels included in our analysis from 2017 to 2025 (Figure 1.12, Table 1.7).
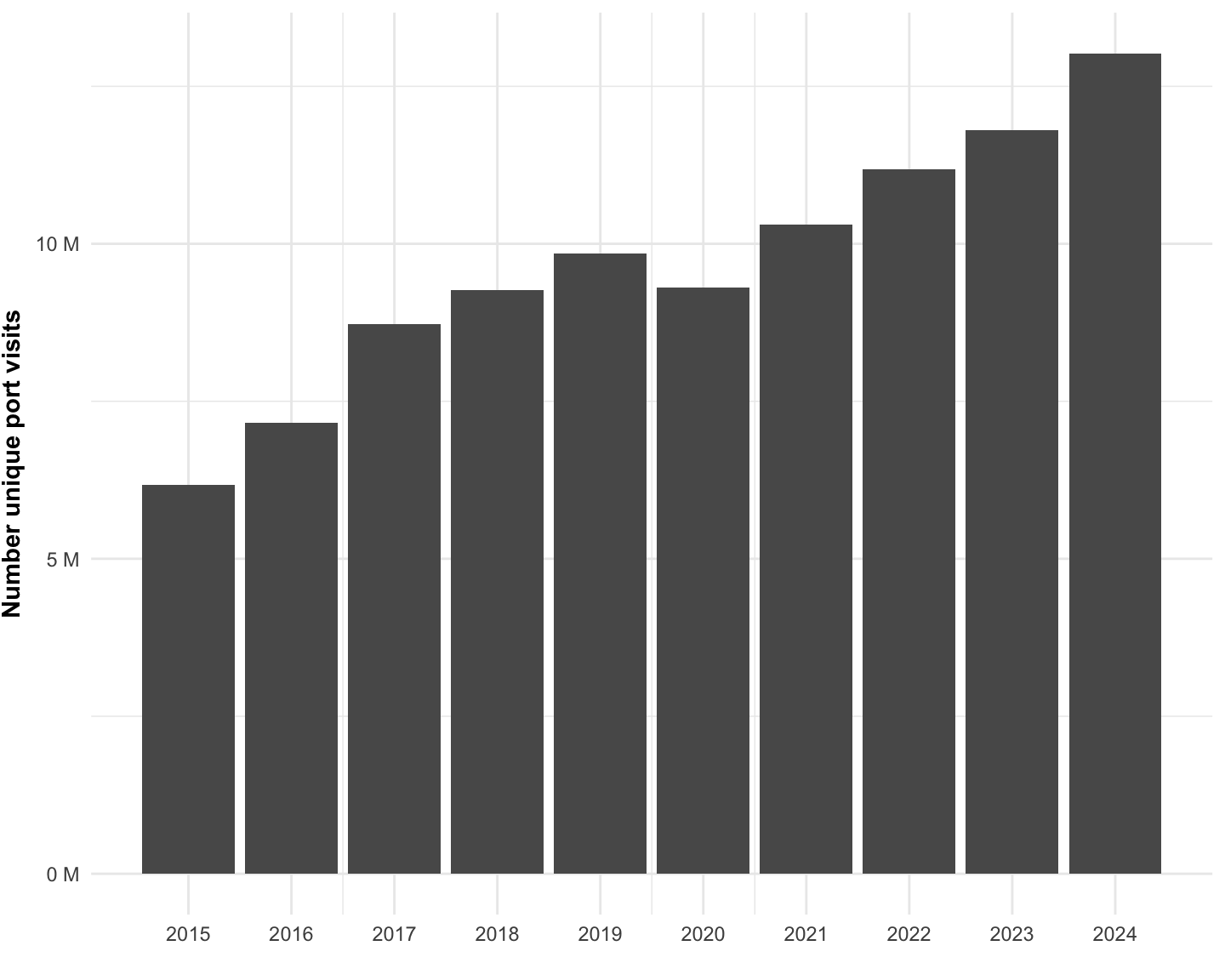
| year | n_unique_events |
|---|---|
| 2015 | 6,130,216 |
| 2016 | 7,124,172 |
| 2017 | 8,667,809 |
| 2018 | 9,198,527 |
| 2019 | 9,779,050 |
| 2020 | 9,175,022 |
| 2021 | 10,136,190 |
| 2022 | 11,077,488 |
| 2023 | 11,724,776 |
| 2024 | 12,878,004 |
| 2025 | 13,839,342 |
1.2.1.4 Emissions
Next, we look at total annual global emissions (metric tonnes, MT) for each pollutant from 2017 to 2025 (Figure 1.13, Table 1.8).

| year | CO2 | NOX | SOX | CH4 | CO | N2O | PM10 | PM2_5 | VOCS |
|---|---|---|---|---|---|---|---|---|---|
| 2015 | 707,471,601 | 12,014,971 | 4,375,602 | 18,230 | 530,846 | 34,214 | 1,249,092 | 1,148,475 | 693,453 |
| 2016 | 774,813,461 | 13,004,975 | 4,791,398 | 19,262 | 576,000 | 37,429 | 1,367,039 | 1,256,921 | 757,848 |
| 2017 | 847,525,186 | 14,002,871 | 5,240,045 | 20,480 | 622,897 | 40,882 | 1,494,272 | 1,373,905 | 827,174 |
| 2018 | 883,485,973 | 14,393,721 | 5,460,873 | 22,232 | 643,981 | 42,583 | 1,557,942 | 1,432,446 | 862,728 |
| 2019 | 903,871,255 | 14,485,043 | 5,585,446 | 22,735 | 654,005 | 43,536 | 1,595,120 | 1,466,629 | 884,737 |
| 2020 | 894,332,507 | 14,151,232 | 1,105,352 | 19,940 | 641,837 | 43,091 | 325,256 | 299,056 | 876,476 |
| 2021 | 959,211,332 | 15,090,561 | 1,185,546 | 21,012 | 684,894 | 46,190 | 348,470 | 320,400 | 936,915 |
| 2022 | 1,022,338,834 | 15,892,915 | 1,263,217 | 24,405 | 728,966 | 49,184 | 371,569 | 341,638 | 999,927 |
| 2023 | 1,070,420,615 | 16,593,335 | 1,322,687 | 25,543 | 768,336 | 51,516 | 389,513 | 358,137 | 1,050,832 |
| 2024 | 1,153,316,678 | 17,699,998 | 1,425,041 | 26,596 | 821,956 | 55,470 | 419,317 | 385,540 | 1,129,221 |
| 2025 | 1,202,323,751 | 18,294,594 | 1,485,563 | 27,154 | 855,256 | 57,815 | 437,309 | 402,082 | 1,178,653 |
1.2.2 Emissions by vessel class
Next, for2025, we summarize the global annual emissions by vessel class (Figure 1.14). These are summarized using the GFW vessel class categories. We first plot simply CO2 emissions, then look at a table of all pollutants.
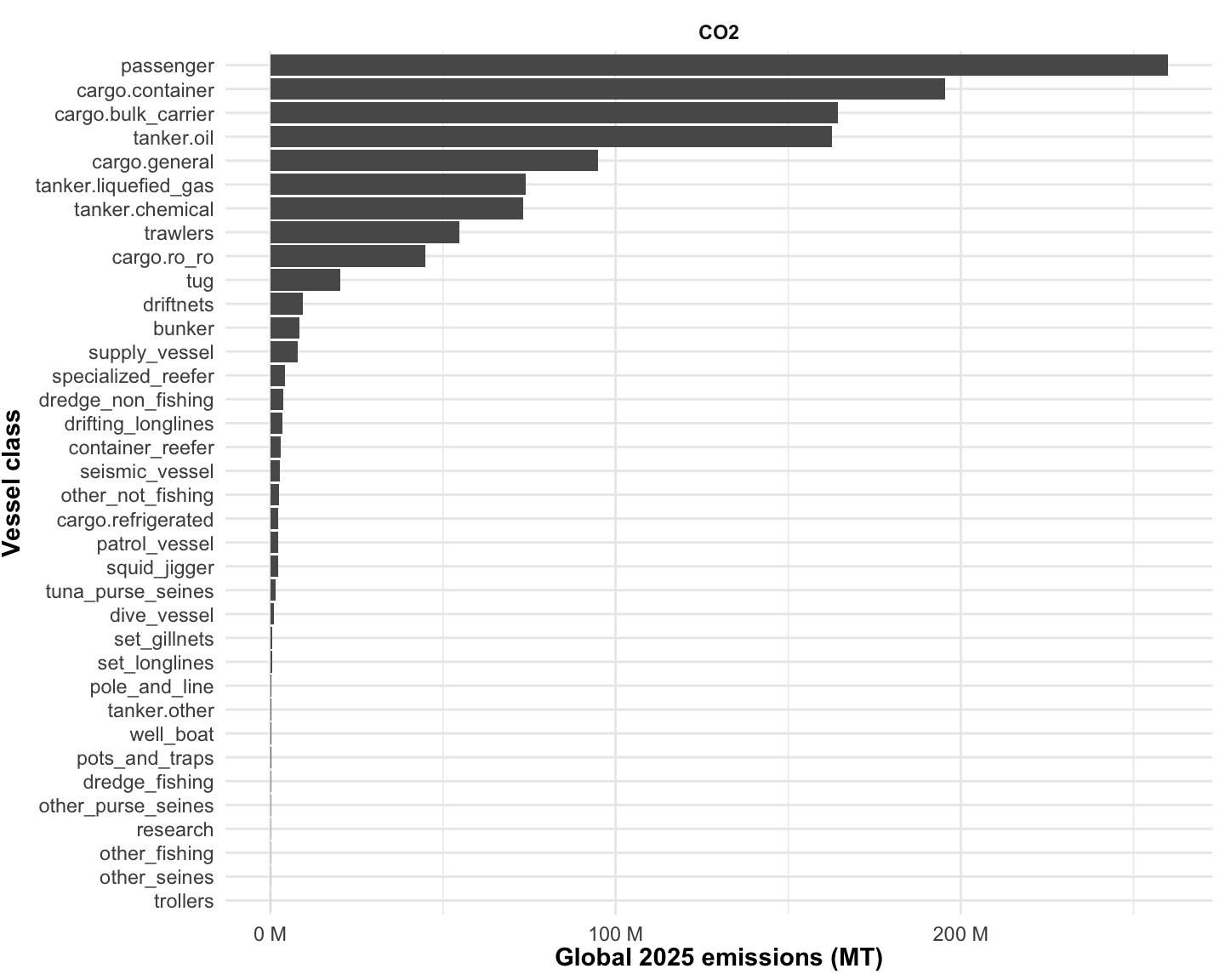
We next can look at a table of all pollutants for 2025 (Table 1.9):
| vessel_class | CO2 | NOX | SOX | VOCS | CO | PM10 | PM2_5 | N2O | CH4 |
|---|---|---|---|---|---|---|---|---|---|
| passenger | 259,900,096 | 1,874,902 | 318,006 | 247,885 | 114,371 | 93,700 | 86,152 | 11,967 | 6,867 |
| cargo.container | 195,507,266 | 4,207,729 | 243,062 | 203,207 | 178,867 | 72,503 | 66,663 | 9,850 | 3,730 |
| cargo.bulk_carrier | 164,371,271 | 3,427,250 | 204,373 | 158,798 | 142,429 | 59,506 | 54,713 | 8,173 | 2,701 |
| tanker.oil | 162,626,273 | 2,171,380 | 200,579 | 155,230 | 101,290 | 58,646 | 53,922 | 7,770 | 1,788 |
| cargo.general | 95,024,501 | 1,384,680 | 117,586 | 94,177 | 72,179 | 34,685 | 31,891 | 4,531 | 1,988 |
| tanker.liquefied_gas | 73,893,796 | 1,181,970 | 91,374 | 71,646 | 51,182 | 26,782 | 24,624 | 3,573 | 1,023 |
| tanker.chemical | 73,331,882 | 1,103,335 | 90,647 | 69,738 | 50,396 | 26,413 | 24,286 | 3,516 | 909 |
| trawlers | 54,784,192 | 917,567 | 67,996 | 51,114 | 44,064 | 19,614 | 18,034 | 2,518 | 817 |
| cargo.ro_ro | 44,832,116 | 862,393 | 55,568 | 43,315 | 37,060 | 16,230 | 14,923 | 2,176 | 1,789 |
| tug | 20,300,094 | 324,353 | 25,180 | 25,426 | 19,103 | 8,045 | 7,397 | 1,007 | 402 |
| driftnets | 9,543,526 | 151,748 | 11,840 | 8,904 | 7,570 | 3,417 | 3,142 | 444 | 140 |
| bunker | 8,421,099 | 55,470 | 10,309 | 7,952 | 3,378 | 3,026 | 2,783 | 388 | 53 |
| supply_vessel | 7,914,681 | 110,276 | 9,817 | 8,935 | 6,994 | 3,020 | 2,776 | 385 | 140 |
| specialized_reefer | 4,258,473 | 63,084 | 5,270 | 4,053 | 3,102 | 1,534 | 1,411 | 201 | 57 |
| dredge_non_fishing | 3,864,228 | 61,356 | 4,793 | 4,069 | 3,261 | 1,439 | 1,323 | 185 | 64 |
| drifting_longlines | 3,470,753 | 62,510 | 4,308 | 3,238 | 2,798 | 1,243 | 1,143 | 163 | 52 |
| container_reefer | 3,060,022 | 67,750 | 3,801 | 2,899 | 2,540 | 1,101 | 1,012 | 149 | 47 |
| seismic_vessel | 2,709,211 | 42,906 | 3,344 | 3,448 | 2,598 | 1,080 | 993 | 134 | 322 |
| other_not_fishing | 2,528,432 | 31,887 | 3,118 | 2,652 | 1,659 | 940 | 865 | 121 | 31 |
| cargo.refrigerated | 2,315,998 | 41,659 | 2,847 | 2,200 | 1,897 | 834 | 767 | 111 | 292 |
| patrol_vessel | 2,231,921 | 32,181 | 2,524 | 2,692 | 2,592 | 872 | 802 | 108 | 3,830 |
| squid_jigger | 2,228,950 | 34,593 | 2,766 | 2,080 | 1,792 | 798 | 734 | 104 | 33 |
| tuna_purse_seines | 1,433,333 | 23,849 | 1,779 | 1,337 | 1,154 | 513 | 472 | 66 | 21 |
| dive_vessel | 944,393 | 12,947 | 1,172 | 998 | 809 | 352 | 324 | 45 | 16 |
| set_gillnets | 649,402 | 11,133 | 806 | 606 | 519 | 233 | 214 | 30 | 10 |
| set_longlines | 483,349 | 8,130 | 600 | 451 | 386 | 173 | 159 | 22 | 7 |
| pole_and_line | 375,775 | 6,664 | 466 | 351 | 300 | 135 | 124 | 17 | 6 |
| tanker.other | 253,665 | 1,950 | 311 | 239 | 107 | 91 | 84 | 12 | 2 |
| well_boat | 235,455 | 3,519 | 292 | 230 | 192 | 86 | 79 | 11 | 4 |
| pots_and_traps | 230,732 | 4,347 | 286 | 215 | 185 | 83 | 76 | 11 | 3 |
| dredge_fishing | 174,856 | 3,427 | 217 | 163 | 139 | 63 | 58 | 8 | 3 |
| other_purse_seines | 146,496 | 2,899 | 182 | 137 | 117 | 52 | 48 | 7 | 2 |
| research | 98,679 | 1,645 | 122 | 101 | 82 | 36 | 33 | 5 | 2 |
| other_fishing | 81,576 | 1,186 | 101 | 76 | 66 | 29 | 27 | 4 | 1 |
| other_seines | 58,992 | 1,144 | 73 | 55 | 47 | 21 | 19 | 3 | 1 |
| trollers | 38,267 | 775 | 47 | 36 | 31 | 14 | 13 | 2 | 1 |
1.2.3 Spatial maps of emissions
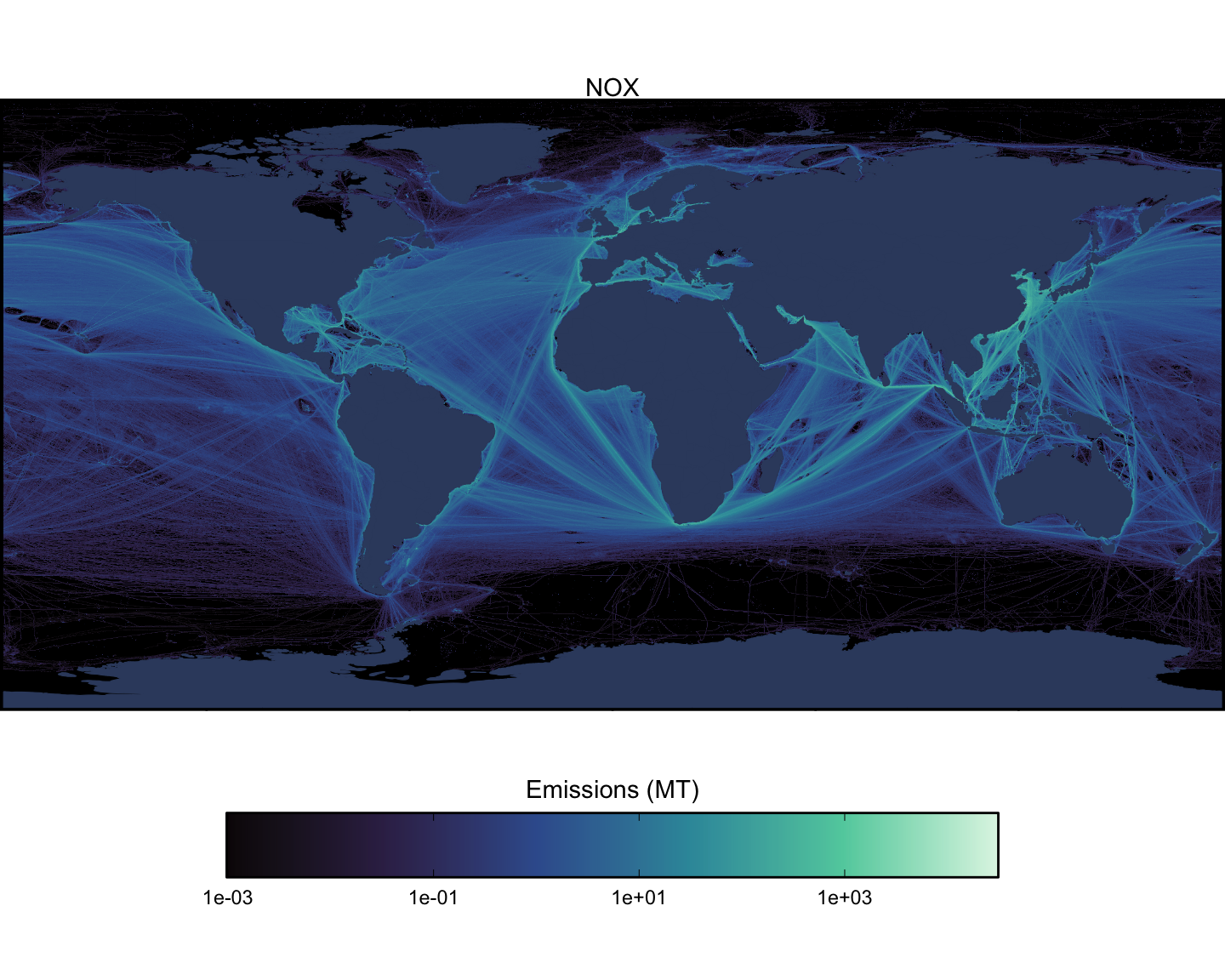
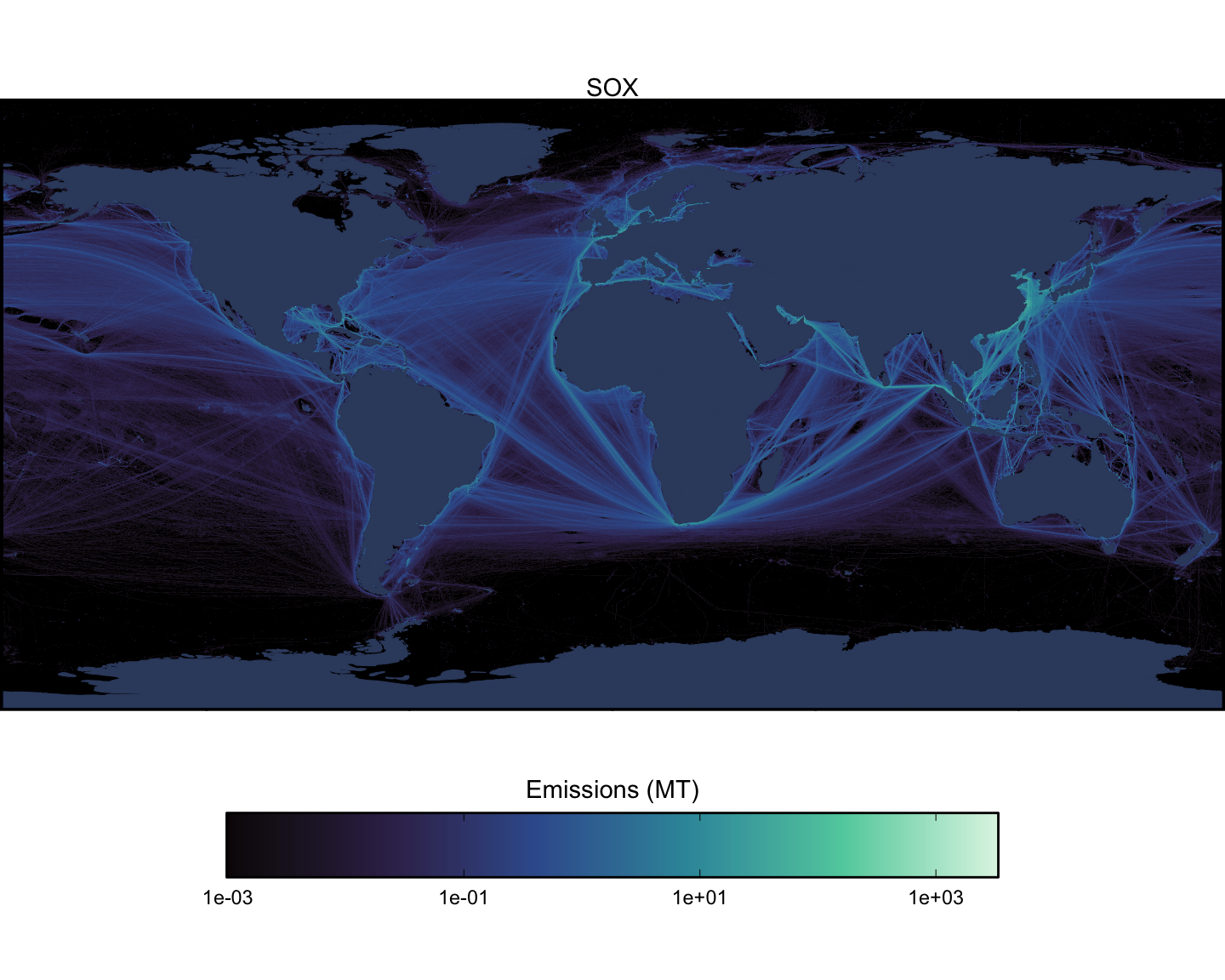
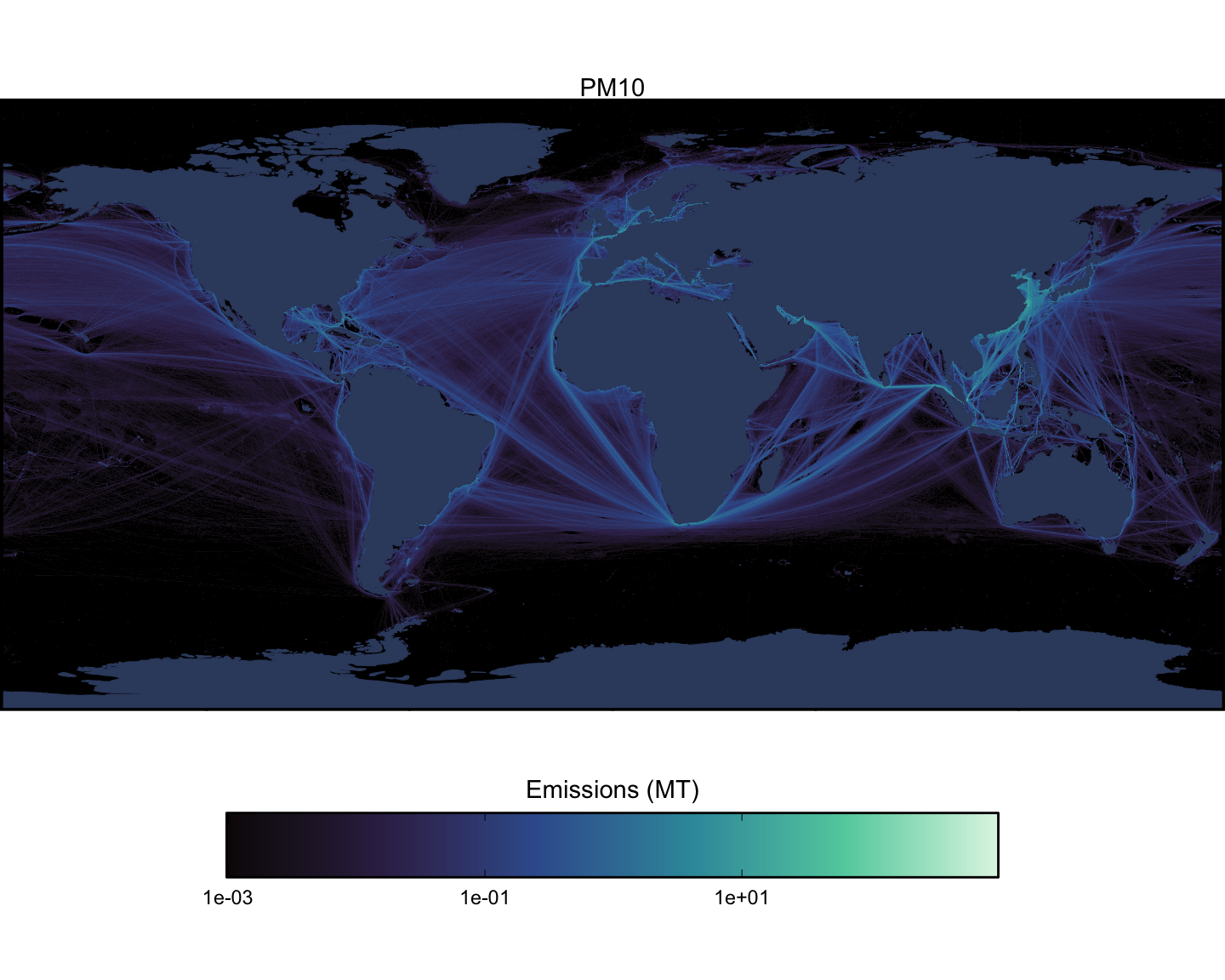
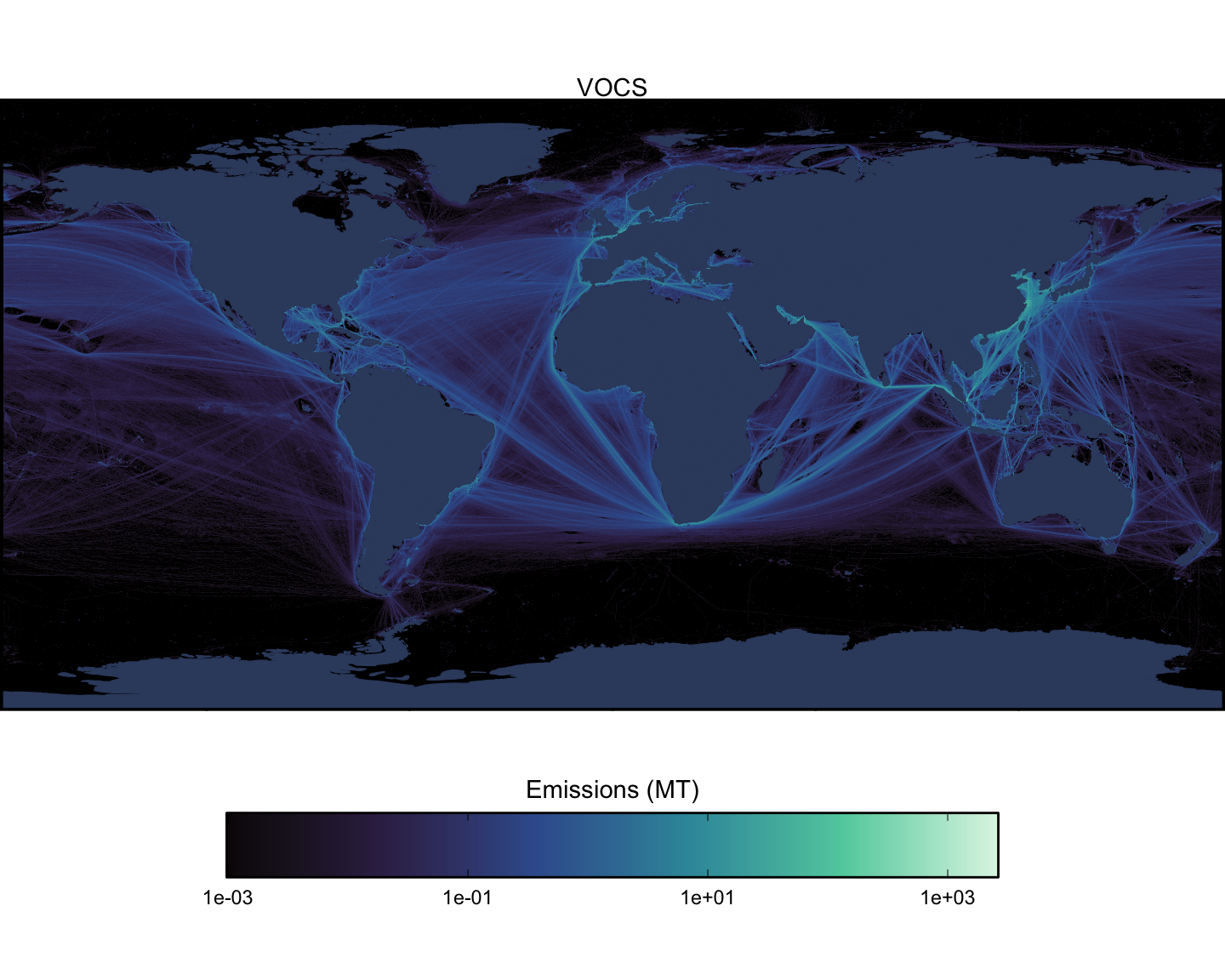
Next we can look at spatial maps of emissions by pollutant, aggregated across all vessel types. These maps are shown at a spatial resolution of 0.1x0.1 degrees (Figure 1.15 - Figure 1.23).
Reading layer `World_Countries_Generalized' from data source
`/Users/gmcdonald/github/ocean-ghg/data/raw/World_Countries_Generalized_Shapefile/World_Countries_Generalized.shp'
using driver `ESRI Shapefile'
Simple feature collection with 251 features and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -20037510 ymin: -30240970 xmax: 20037510 ymax: 18418390
Projected CRS: WGS 84 / Pseudo-Mercator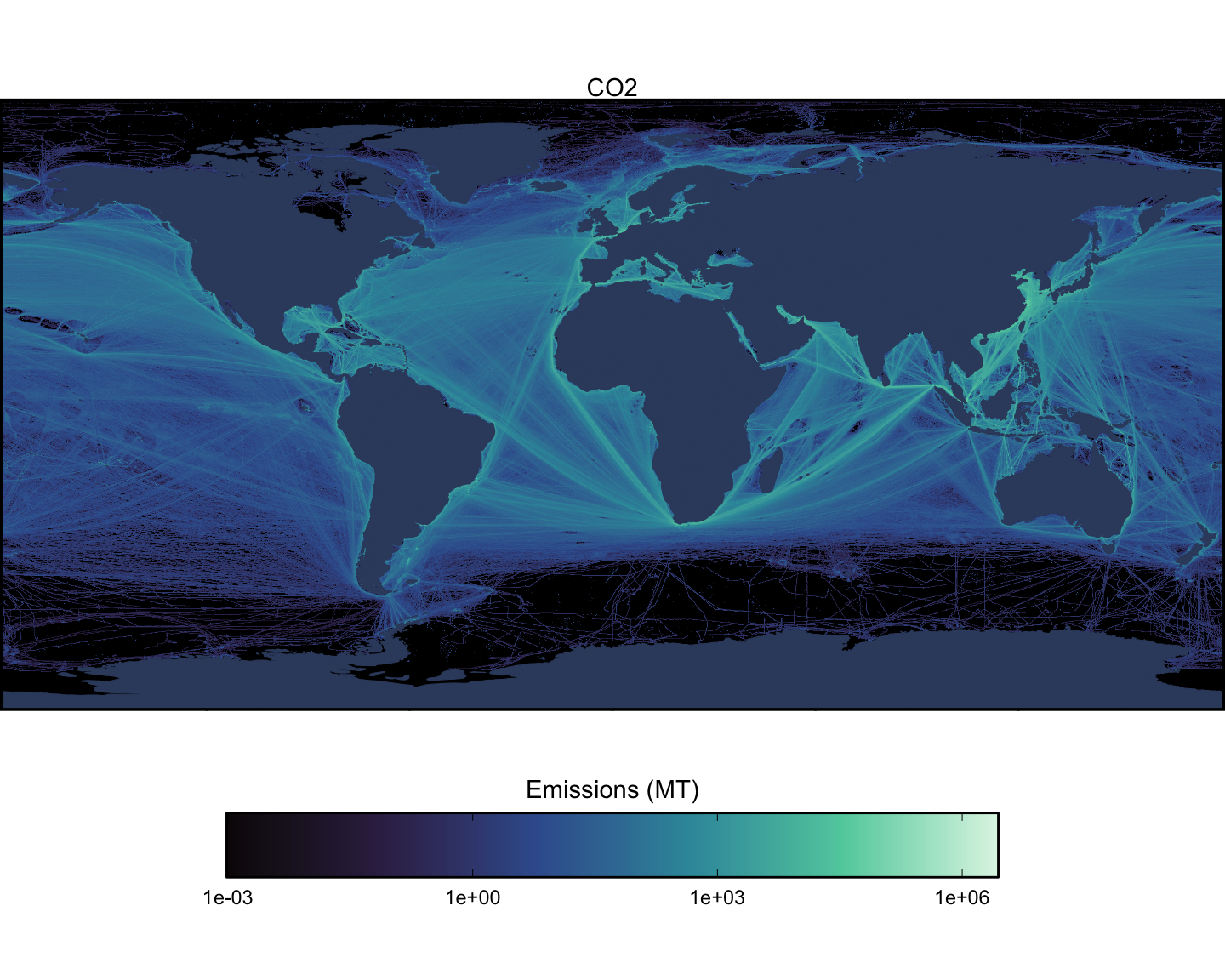
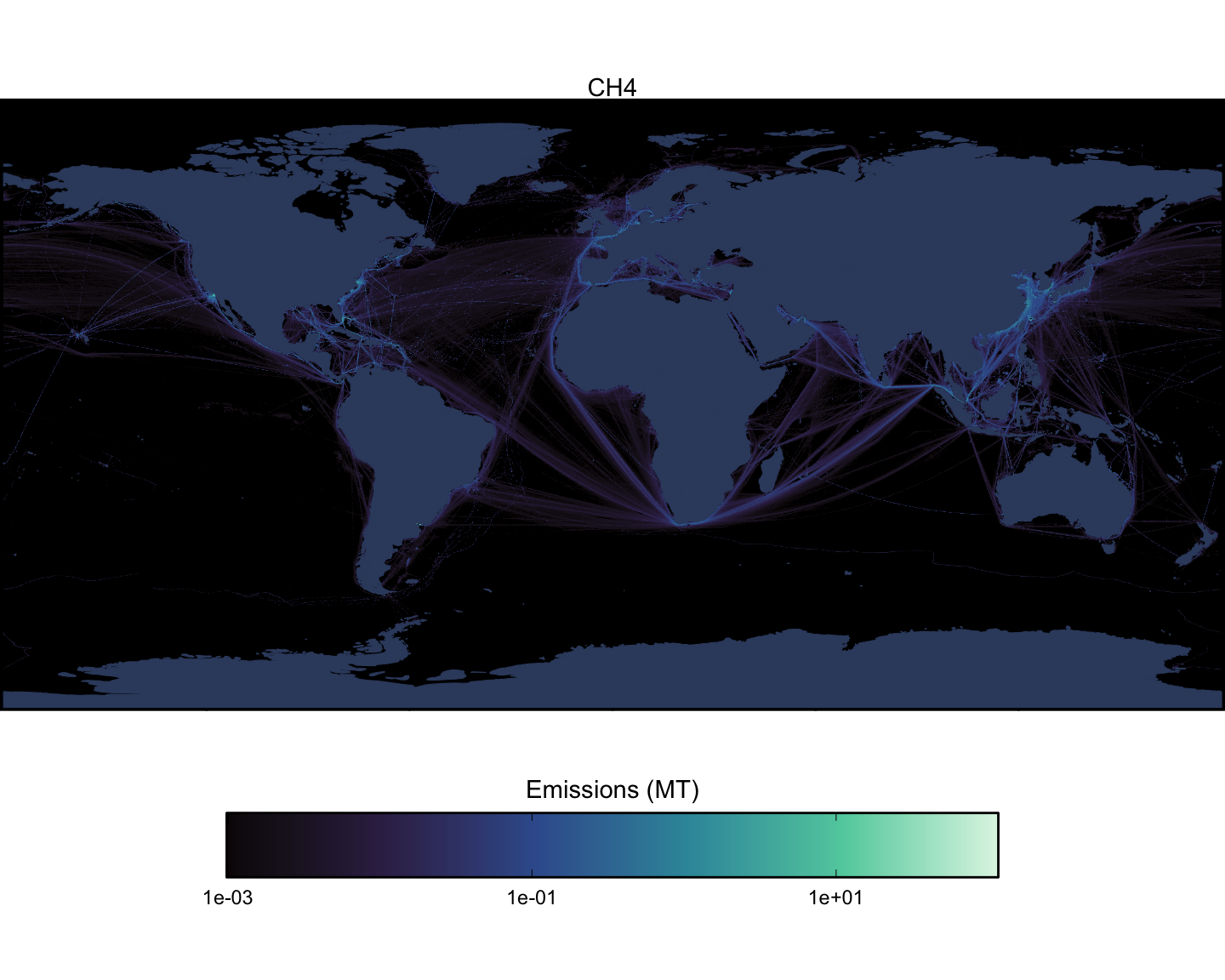
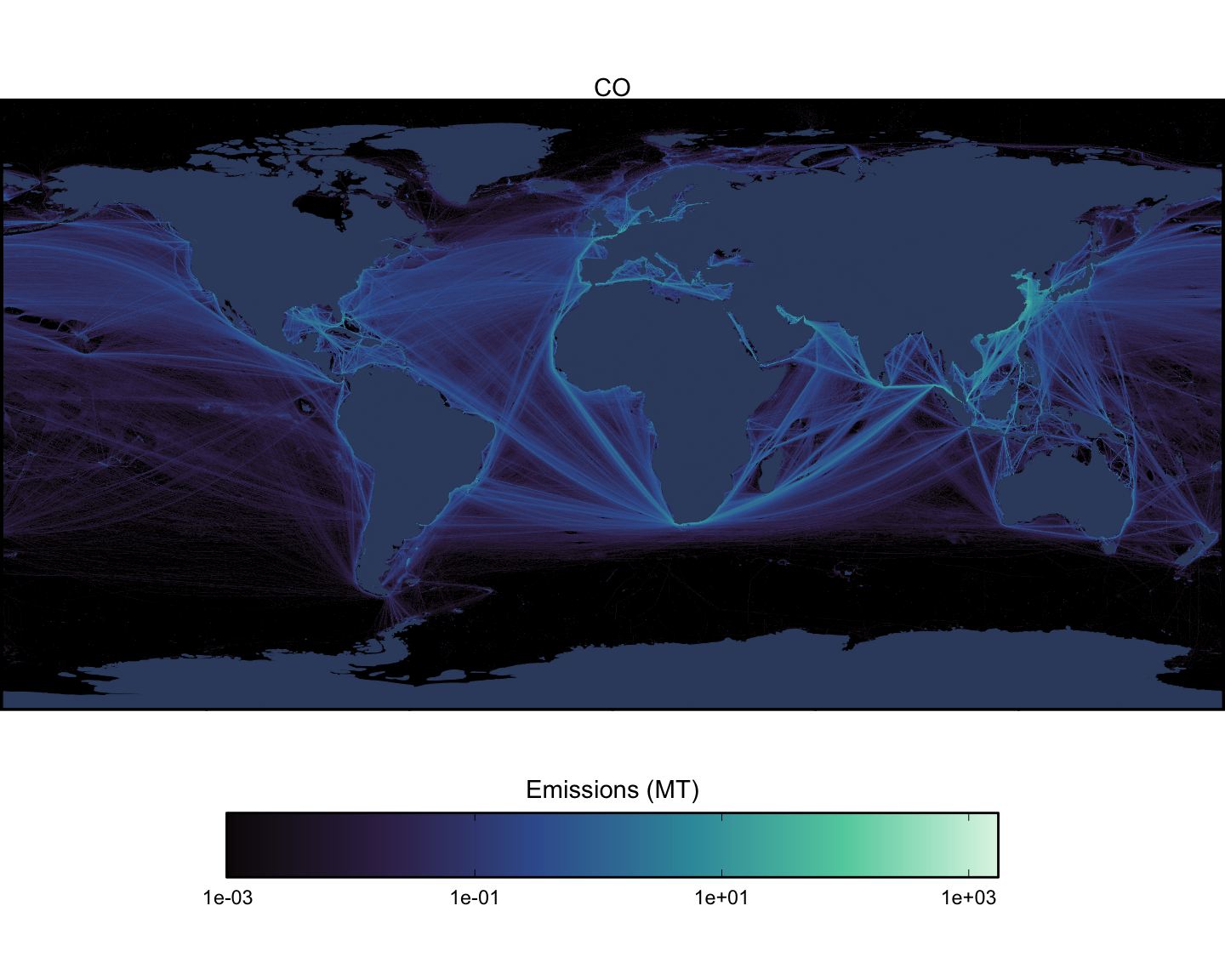
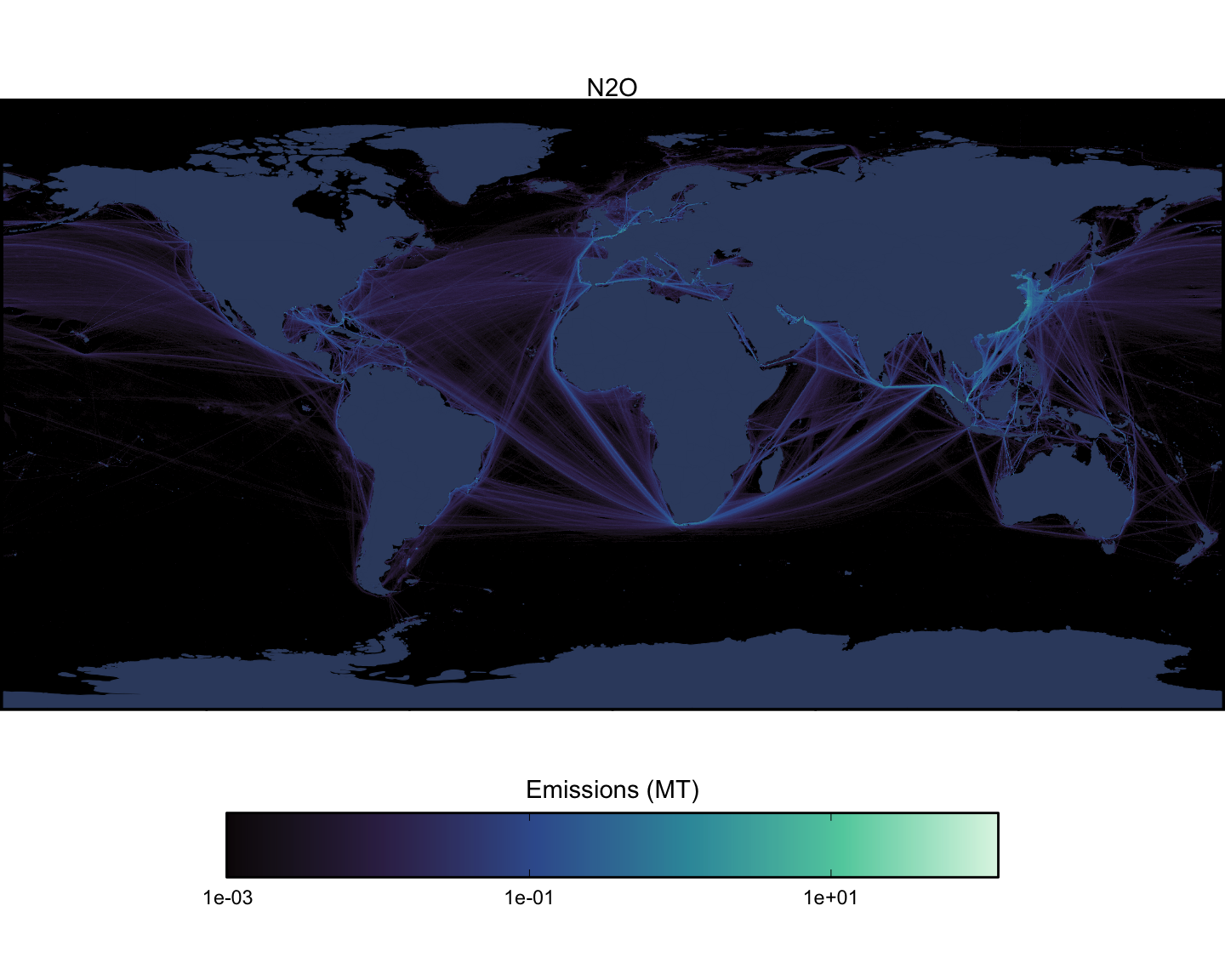
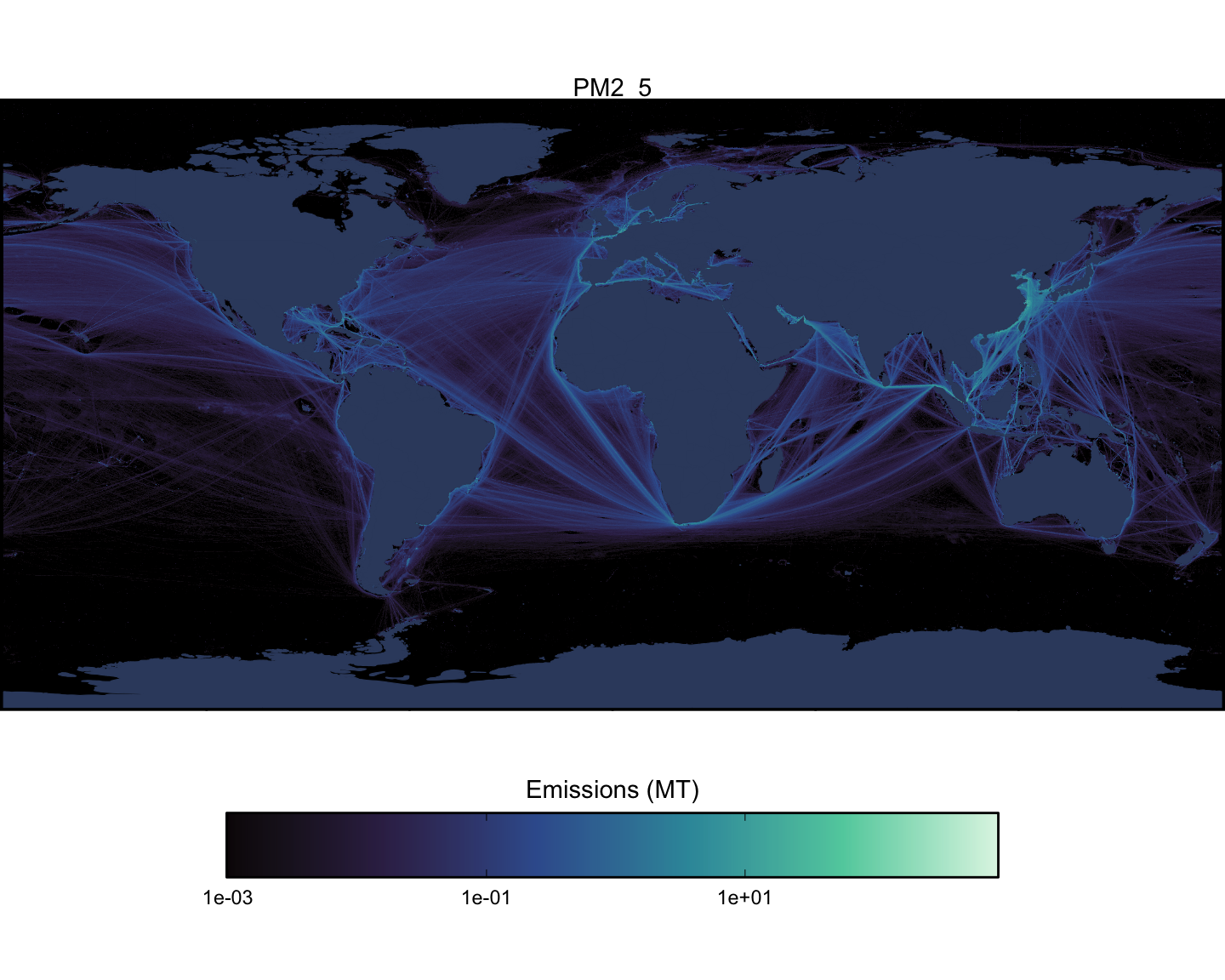
1.3 Model Validation
The initial stages of model development involved multiple rounds of preliminary validation against testing model versions to identify the best-performing one among those evaluated. Following this testing phase, and with the AIS-based model built as described above, we validated it against measured absolute emission values from a dataset of a European Union (EU) monitoring program.
1.3.1 EU emissions data
We used the \(CO_2\) emissions data from maritime transport provided by the European Maritime Safety Agency, which is part of the monitoring, reporting, and verification program of carbon emissions from maritime transport, set by the Regulation (EU) 2015/757. As detailed below, vessels with certain characteristics and certain trips made by such vessels operating in EEA sea ports, must report their emissions on an annual basis.
1.3.1.1 What’s in an out of EU 2015/757
Here, we summarize the relevant provisions of this legislation that define the vessels and trip characteristics that need to be filtered from our data for validation purposes.
Vessel characteristics:
Ships above 5000 gross tonnage.
Excludes warships, naval auxiliaries, fish-catching or fish-processing ships, wooden ships of a primitive build, ships not propelled by mechanical means, or government ships used for non-commercial purposes.
Trips characteristics:
Trips from their last port of call to a port of call under the jurisdiction of a Member State and from a port of call under the jurisdiction of a Member State to their next port of call, as well as within ports of call under the jurisdiction of a Member State.
Vessel activities covered by the law are those when the ships are at sea as well as at berth.
Ship at berth includes any ship which is securely moored or anchored in a port falling under the jurisdiction of a Member State while it is loading, unloading or hotelling, including the time spent when not engaged in cargo operations.
Port of call means the port where a ship stops to load or unload cargo or to embark or disembark passengers; consequently, stops for the sole purposes of refueling, obtaining supplies, relieving the crew, going into dry-dock or making repairs to the ship and/or its equipment, stops in port because the ship is in need of assistance or in distress, ship-to-ship transfers carried out outside ports, and stops for the sole purpose of taking shelter from adverse weather or rendered necessary by search and rescue activities are excluded.
Ship to ship transfers carried out outside ports are covered by the Regulation when these transfers take place as part of a voyage starting and/or ending with a port of call under the jurisdiction of a Member State.
A ship to ship transfer carried out outside ports is not considered as a port of call. As a consequence, if for example, a vessel leaves an EEA port, arrives to a US harbor performs a ship to ship operation outside the port limits, and then goes to South Corea the emissions falling within MRV scope will be the emissions released during the whole voyage from the EEA port of call until the port of call in South Korea. However, if the ship to ship transfer can be carried out within the port limits, that operation would constitute a port of call. The voyage covered by the MRV Maritime Regulation would then be an EEA port of call to a US port of call.
If a ship performs more than 300 voyages during the reporting period and all of these voyages either start from or end in a port within a Member State, the company can be exempted from monitoring the detailed parameters for each voyage.
Time ranges:
- The reporting period covers one calendar year during which CO2 emissions have to be monitored. For voyages starting and ending in two different calendar years, the monitoring and reporting data shall be accounted under the first calendar year concerned.
1.3.2 Data filtering
Given the law’s exceptions, in order to validate emission estimates, we need to filter our results to match the EU data contents and aggregation. In this regard, the vessel characteristics in terms of type and gross tonnage can be filtered by simply assessing which vessel IDs are included in the EU dataset. As for the time range, since the data is aggregated yearly by the starting date of a trip, the filtering is straightforward.
The most challenging aspect of this data filtering corresponds to the trip characteristics, specifically when defining the “ports of call.” The main obstacle is the inability to determine the type of activity a vessel is engaged in while in port, which prevents us from identifying which trips are included within those aggregated yearly emissions. To work around this, and establish which vessels’ emissions can be included in the validation, we have compared the total distance and total hours at sea reported in the EU data to the total distance traveled across all trips in our trip-level emissions for that vessel and year. If these numbers were within ±5%, ±10%, or ±15% difference, then we could reasonably assumed that aggregated trips in the GFW dataset correspond to trips included in the EU dataset.
The EU data has been compiled and stored in proj_ocean_ghg.eu_validation_data, while the selection and part of the filtering from our data has been conducted through the queries in eu_validation_trip.sql and eu_validation_port.sql, differentiating between emissions by trip and port visits, and stored in proj_ocean_ghg.eu_validation_trip and proj_ocean_ghg.eu_validation_port respectively.
1.3.3 Validation results
Emissions estimates are divided between emissions at sea and emissions at port. Here, we present the differences between our results and the EU emissions data.
1.3.3.1 Trip emissions
As detailed in the Methods section, we have defined trip emissions as those occurring between ports. In the EU dataset, these emissions are categorized under three variables: emissions from EEA-EEA, EEA-NonEEA, and NonEEA-EEA seaports. We have run our model, selected the data by trips involving at least one EEA port, aggregated the results by year, and selected vessels listed in the EU dataset for a specific year.
After discarding 1063 observations with no time at sea, and assessing potential duplicates due to different ssvid for the same imo_number (0 duplicates in this dataset), we ended up with a total of 212530 observations—year and vessel—selected from our emission estimates. This is 86.4% of the EU data observations. By applying different margin values to the annual hours at sea we get the following performance metrics detailed in Table 1.10. As we can see, higher performance is achieved applying a 10% margin, with which we obtained a selection of 1594 observations for validation.
| mae | rmse | nrmse | rsq | rsq_trad | mape | mpe | threshold | n_observations |
|---|---|---|---|---|---|---|---|---|
| 2233.234 | 5571.797 | 0.511 | 0.767 | 0.738 | Inf | -Inf | 0.05 | 921 |
| 2306.633 | 5312.249 | 0.484 | 0.782 | 0.766 | Inf | -Inf | 0.10 | 1594 |
| 2378.678 | 5267.049 | 0.467 | 0.790 | 0.782 | Inf | -Inf | 0.15 | 2275 |
| 2492.823 | 5718.965 | 0.519 | 0.756 | 0.731 | Inf | -Inf | 0.20 | 2911 |
| 2615.588 | 5684.895 | 0.509 | 0.768 | 0.741 | Inf | -Inf | 0.25 | 3600 |
| 2863.099 | 7026.074 | 0.619 | 0.700 | 0.617 | Inf | -Inf | 0.30 | 4375 |
| 3129.187 | 7600.968 | 0.667 | 0.701 | 0.554 | Inf | -Inf | 0.35 | 5256 |
| 3573.343 | 8312.568 | 0.714 | 0.716 | 0.490 | Inf | -Inf | 0.40 | 6301 |
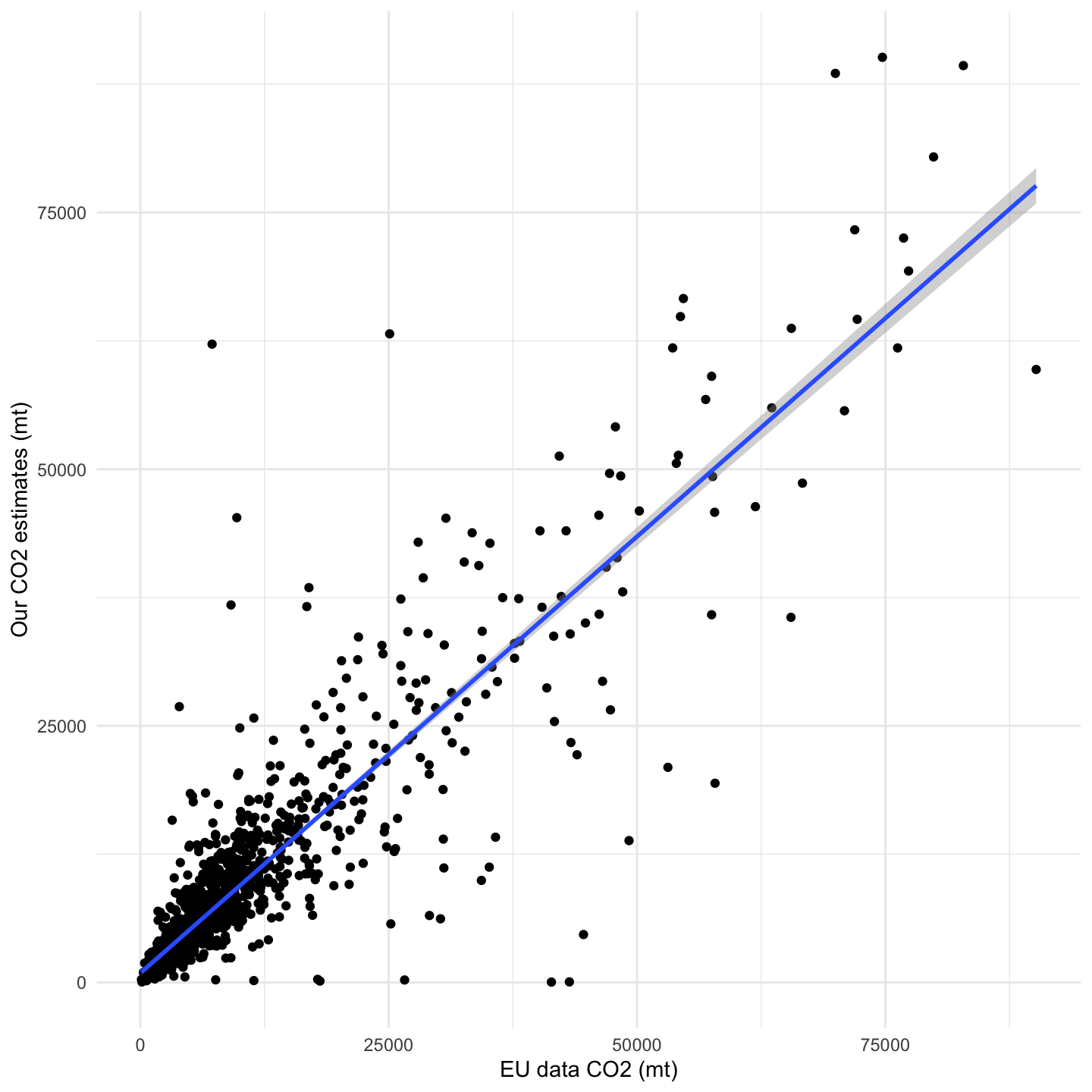
Comparing against the EU dataset with that 10% margin, the model demonstrates a good fit with an R-squared value of 0.78. While the MAE and RMSE indicate a considerable average magnitude of prediction errors, we need to consider that the average emission values are quite large since we are estimating absolute emissions per year. In fact, the normalized RMSE suggests that the errors, relative to the range of observed values, are moderate. Further, the model exhibits a tendency to underestimate emissions, as evidenced by the MPE. Despite some limitations, this validation framework offers a useful alternative to the one derived from the ML results, avoiding the related outlier inconveniences from emissions expressed in distance units. We can visually explore the relationship between our results and the EU data, observing certain linearity between both emission values with some spreading as the emission values increase (Figure 1.24).
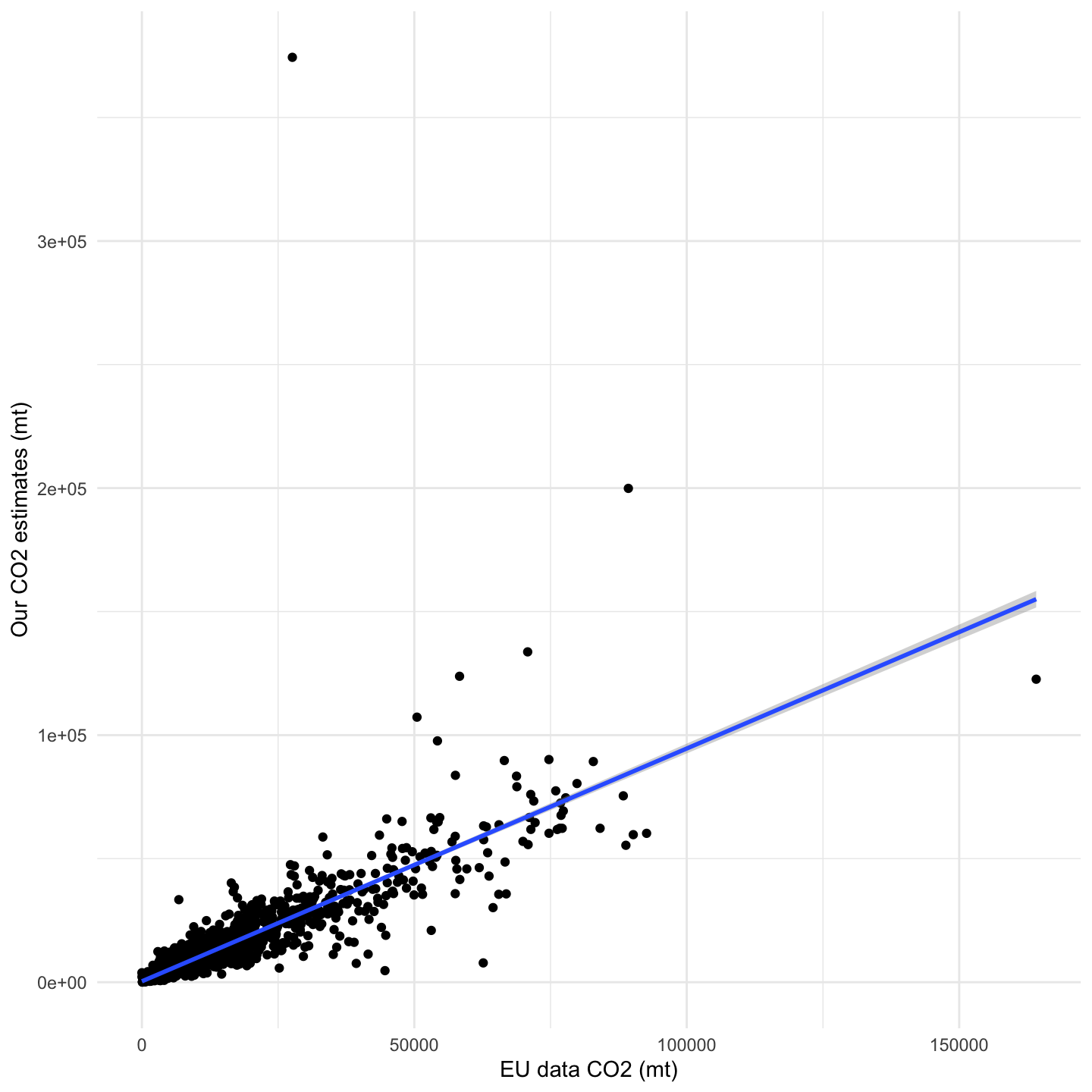
We can double-check these results by applying the data filtering margin on distance traveled instead of hours. In this regard, while the EU dataset does not contain information on the total nautical miles (nm) navigated, we can extract this from the annual average \(CO_2\) emissions per distance. If we apply distinct margins to the total nautical miles (nm) navigated, we achieve the highest performance values for the 25% margin, with which we select 3500 observations. Overall, the performance metrics are slightly worse than those obtained by using hours at sea, which was a direct measure available in the EU dataset, rather than an indirect estimate like total nm navigated (Figure 1.25 and Table 1.11).
| mae | rmse | nrmse | rsq | rsq_trad | mape | mpe | threshold | n_observations |
|---|---|---|---|---|---|---|---|---|
| 1793.453 | 3906.449 | 0.371 | 0.866 | 0.862 | 21.61 | 6.512 | 0.05 | 1132 |
| 1817.050 | 3816.339 | 0.358 | 0.878 | 0.872 | Inf | -Inf | 0.10 | 1710 |
| 1913.120 | 3963.890 | 0.348 | 0.885 | 0.879 | Inf | -Inf | 0.15 | 2326 |
| 2112.865 | 8133.181 | 0.721 | 0.602 | 0.480 | Inf | -Inf | 0.20 | 2883 |
| 2201.355 | 7946.290 | 0.692 | 0.641 | 0.521 | Inf | -Inf | 0.25 | 3500 |
| 2336.231 | 7690.933 | 0.670 | 0.667 | 0.551 | Inf | -Inf | 0.30 | 4199 |
| 2550.791 | 7546.033 | 0.660 | 0.688 | 0.564 | Inf | -Inf | 0.35 | 4996 |
| 2839.144 | 7571.756 | 0.648 | 0.722 | 0.580 | Inf | -Inf | 0.40 | 5993 |
1.3.3.2 Port emissions
As for emissions at ports, these consist of emissions during port stays. Here, we have filtered those emission results by port visits within the EEA and followed the same aggregation procedure as for trips. However, some assumptions have been made due to the impossibility of filtering out stays that may not be included in the EU dataset. As mentioned earlier, one of the inconveniences related to using this dataset is the definition of “ports of call”, which establishes whether a vessel trip and port visit is considered or not under the regulation and, by extension, whether its emissions are reported and available in the EU dataset. Unable to define the activities performed by a vessel in a port, we assume that we will be overestimating the emissions at port since the EU does not include them all. With it, and applying the same procedure, we see that the performance values are quite poor given that overestimation, leaving us with the need to find an alternative way to validate our port emission results while improving our models estimates (Table 1.12 and Figure 1.26).
| model | mae | rmse | nrmse | rsq | rsq_trad | mape | mpe |
|---|---|---|---|---|---|---|---|
| Model 6.3 | 7389.532 | 16545.48 | 12.213 | 0.169 | -148.149 | Inf | -Inf |
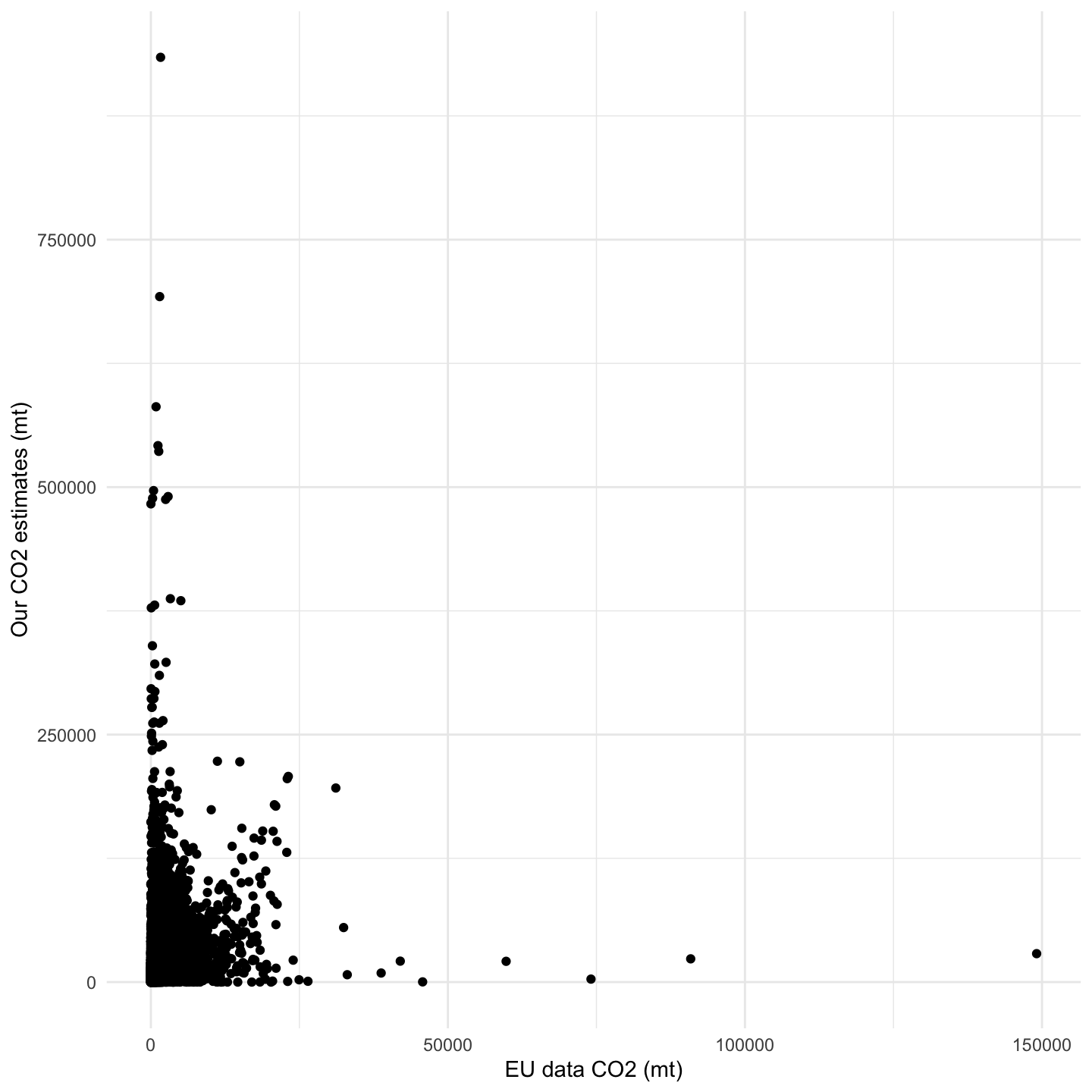
By applying an additional filtering step, selecting those observations from the trips under the 10% hours at sea margin approach, we would expect to narrow down our observations to those actually happening under “ports of call”. However, as the performance values in Table 1.13 and the emissions relationship shown in Figure 1.27 indicate, our model still does not capture emissions at port as reflected in the EU dataset, highlighting the need for improvement in this aspect.
| model | mae | rmse | nrmse | rsq | rsq_trad | mape | mpe |
|---|---|---|---|---|---|---|---|
| Model 6.3 | 1505.32 | 7142.501 | 4.891 | 0.083 | -22.937 | Inf | -Inf |
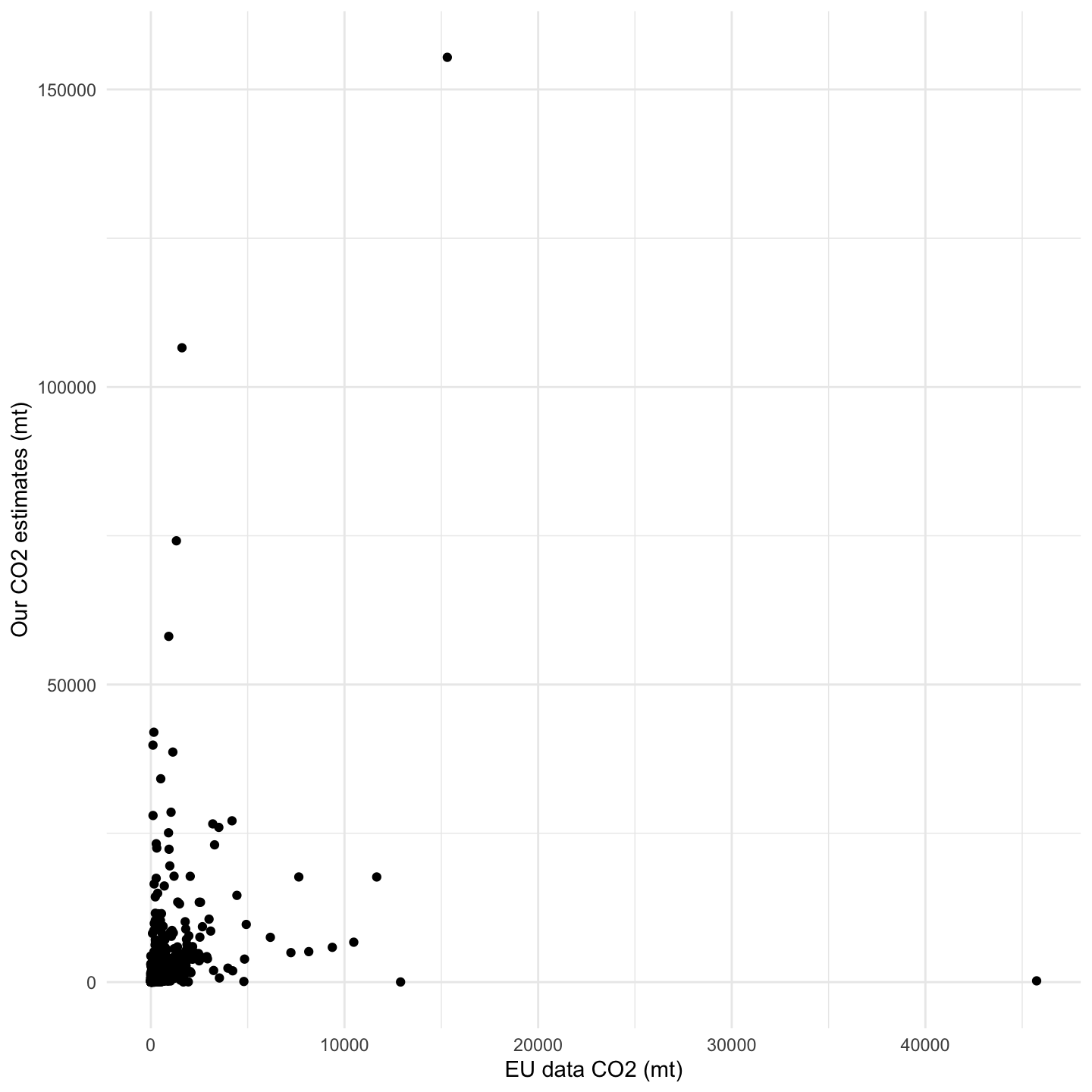
1.3.4 Comparison to other global emissions estimates
Several other emissions estimates have been done by the International Maritime Organization (IMO) (most recently for 2018), Emissions Database for Global Atmospheric Research (EDGAR) in (most recently for 2024), Organization for Economic Co-operation and Development (OECD) (most recently for 2024 using their experimental database). Below we compare our GHG emissions estimates with the findings of these studies to validate our results
The emissions inventories used in this comparison rely on a range of methods and have some differences in sector definitions and underlying data sources. Here we compare the most recent year of data from each inventory.
Highlights include:
GFW’s total estimated emissions (1.51 billion MT CO2 for both AIS-broadcasting vessels and dark vessels, and 1.15 billion MT CO2 for just AIS-broadcasting vessels) are similar to OECD, EDGAR, and IMO, indicating high reliability and utility of our methodology and results.
IMO’s, OECD’s, and EDGAR’s emissions estimates do not include dark fleets, making GFW’s dark fleet estimates the first of their kind.
| CO2 emissions (billion MT) | Data source |
|---|---|
| 1.51 | GFW (2024, AIS + S1) |
| 1.15 | GFW (2024, AIS) |
| 0.97 | OECD (2024) |
| 0.89 | EDGAR (2024) |
| 1.06 | IMO (2018) |